Jak już wiesz z poprzedniego rozdziału bufor danych domyślnie zawiera tylko część DEFAULT. Obiekty w nim się zawierające zostały załadowane tam w momencie kiedy zaszła konieczność sięgnięcia do nich z plików na dysku twardym. Na podstawie algorytmu LRU najdawniej używane obiekty zostają z tego bufora wywalane jeśli bufor się przepełni. Możesz jednak chcieć mieć jakiś obiekt zawsze przechowywany w pamięci bo mimo że sięgasz do niego rzadko, to jednak oczekujesz szybkiego dostępu do niego. Wpierw musisz ustawić sobie wielkość bufora keep :
alter system set db_keep_cache_size=10M;
Teraz możesz wybrane obiekty (tabele albo indeksy) zmienić tak by zawsze były one ładowane do bufora KEEP. Istniejącą tabelę możesz zmienić w ten sposób:
alter table tabela storage (buffer_pool keep);
Możesz również zdefiniować to od razu przy tworzeniu tabeli:
create table tabela2(
kolumna1 number,
kolumna2 varchar2(50)
)storage (buffer_pool keep);
sobota, 11 grudnia 2010
Konfiguracja parametrów SGA
 Zanim zaczniemy konfigurować sobie parametry SGA wypadałoby sprawdzić które z nich są zmienialne w ogóle i które jakie są ich aktualne wartości :)
Zanim zaczniemy konfigurować sobie parametry SGA wypadałoby sprawdzić które z nich są zmienialne w ogóle i które jakie są ich aktualne wartości :)Do sprawdzania obu tych rzeczy mamy specjalne słowniki:
- v$sgainfo - podstawowe informacje o wartościach i informacje czy dane parametr możemy dynamicznie zmieniać czy nie.
- v$sga_dynamic_components - tutaj są informacje znacznie szersze od sgainfo. Mamy też info o aktualnym wykorzystaniu buforów. Jednak nie ma informacji o tym czy dany parametr jest rozszerzalny czy nie.
Sprawdźmy aktualne ustawienia buforów:

Kodzik:
select * from v$sgainfo;
To jaki parametr ustawiamy na jaką wartość zależy od tego do czego nam będzie służyć baza i czego od niej oczekujemy.

Ostatnio bardzo się zdziwiłem kiedy zacząłem zmieniać różne parametry i ku memu wielkiemu zdziwieniu Oracle olewał to co mu ustawiałem. Ja mu ustawiam jakiś parametr a on mi swoje. Chłopaki z Oracla wpadli na przegenialny pomysł by te parametry ustawiały się same, obsrywając to co ustawia admin. To funkcjonuje od wersji 10 Oracle. Niestety nie byli na tyle sprytni by poinformować o tym fakcie jakimś ładnym komunikatem podczas próby ustawienia. Aby nasze zmiany odniosły jakikolwiek skutek musisz wyzerować parametr SGA_TARGET podłóg którego to pozostałe parametry ustawiają się same. SGA_TARGET określa docelową wielkość SGA (nie maksymalną) do jakiej Oracle ma dążyć. Przed ustawianiem czegokolwiek wykonaj więc:
alter system set sga_target=0;
Które to zeruje sga_target jednocześnie wyłączając automagiczne strojenie wielkości buforów. Dopiero teraz możesz zacząć ustawiać pozostałe parametry.
Swoją konfigurację najlepiej zacząć od ustawienia maksymalnej wartości SGA_MAX_SIZE który to parametr określa maksymalną wielkość SGA. Dlatego od tego zaczynamy, bo według tej wartości ustawia się inne parametry które to jako składowe SGA nie mogą sumarycznie przekroczyć jej wartości.
Parametru SGA_MAX_SIZE nie możemy modyfikować dynamicznie, musimy to ustawić w pliku konfiguracyjnym a następnie zrestartować instancję. Zmieniamy więc SGA_MAX_SIZE:
alter system set sga_max_size=700M scope=spfile;
700M to oczywiście 700 megabajtów. Możesz też dać K i wtedy będziesz mógł podać w kilobajtach. SCOPE=SPFILE oznacza że zmiana ma dotyczyć pliku konfiguracyjnego który czytany jest przy starcie instancji.
Zaloguj się jako sys przy użyciu sql plusa ( conn sys/haslo as sysdba ) Teraz zrestartuj instancję:

Kodzik:
Najpierw : SHUTDOWN IMMEDIATE;
Następnie: STARTUP;
Sprawdź aktualną wartość:

Mamy ustawione tak jak chcieliśmy - przy Maximum SGA Size widnieje ustawiona przez nas wartość. Jest ona podana w bajtach, a jak każdy wie 1 kB to 1024 B, a 1MB to 1024kB. Dlatego taka dziwna wartość.
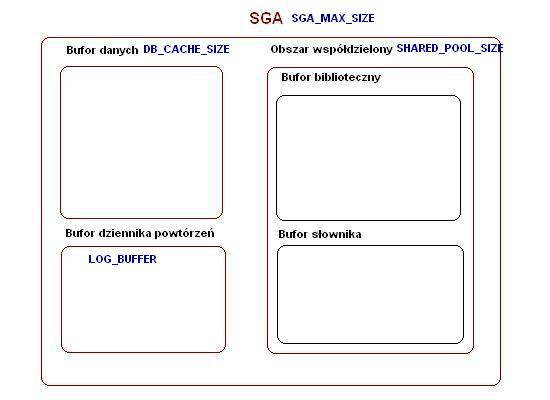
Teraz nazwy buforów i nazwy parametrów:
Bufor danych - DB_CACHE_SIZE
Obszar współdzielony - SHARED_POOL_SIZE
Bufor dziennika powtórzeń - LOG_BUFFER
Bufor Javy - JAVA_POOL_SIZE
Duży bufor - LARGE_POOL_SIZE
Bufor streams - STREAMS_POOL_SIZE
Ustawiam sobie konfigurację dla siebie. Nie będę korzystał z JAVY w Oracle, ani też raczej nie planuję na ten moment jakichś wielkich backupów. Za to oczekuję szybkiego działania bazy danych bez zbędnego oczekiwania na odczyt z dysku. Ustawiam sobie więc db_cache size na 500MB (by mieć dużo rzeczy pod ręką) , java_pool_size i large_pool_size ustawiam na bardzo małe wartości. Obszarowi współdzielonemu też rzucę te 100MB, niech zna łaskę Pana :) Przynajmniej będę miał zbuforowane poparsowane zapytania więc jak będzie mi śmigał duży system to zyskam na czasie parsowania SQLi.

Globalny obszar pamięci SGA
SGA (System Global Area) jest buforem pamięci alokowanym podczas startu instancji. Przechowuje informacje współdzielone przez różne procesy bazy danych. M.in przechowuje:

- Kopie danych z dysku (w buforze danych znajdującym się w SGA)
- Bufor dziennika powtórzeń
- Plany wykonania zapytań SQL
- ...
Generalnie wszystko to co jest potrzebne bazie danych do działania i musi być pod ręką (w pamięci dostępnej dla serwera).

Generalnie SGA dzieli się na kilka części.
Bufor danych - dane do których sięgamy zapytaniem, nie zawsze muszą być czytane z dysku. Jeśli ktoś wcześniej sięgał do danych których nie było w tym buforze, dane te musiały zostać odczytane z dysku a następnie wrzucone do bufora danych. Dzięki temu kiedy następna osoba zarząda tych samych danych, nie będzie już konieczności odczytywania ich z dysku bo będą dostępne w buforze danych. O tym że czas operacji odczytu z pamięci jest nieporównywalnie krótszy od czasu operacji odczytu z dysku jest nieporównywalnie krótszy, chyba nie muszę nikogo przekonywać :).
Działa to też w drugą stronę. Zmieniane czy dodawane dane też nie od razu pakowane są na dysk, są zmieniane najpierw w buforze danych, dzięki czemu są one szybciej dostępne. Oczywiście w pewnym momencie zapisuje je na dysk specjalny proces (DBWR) ale o tym nieco później.
Wiadomo że nie wszystkie dane mogą tu być przechowywane choćby ze względu na pojemność takiego bufora. Jeżeli bufor się przepełni, usuwane są dane najdawniej wykorzystywane. Jeżeli jakieś dane znajdujące się już w buforze zostaną wykorzystane ponownie, trafiają na początek listy. O to dba nam proces serwera. Takie działanie szumnie się nazywa algorytmem LRU (Last Recently Used)
Bufor dziennika powtórzeń - wszystkie zmiany danych są rejestrowane. Dzięki temu, nawet jeśli zmienione dane nie zostały jeszcze trwale zapisane na dysk, jesteśmy w stanie je odtworzyć. Istnieją specjalne pliki dziennika powtórzeń w których zapisywane są wszelkie zmiany, jednak informacja zanim tam trafi, trafia do bufora dziennika powtórzeń.
Bufor biblioteczny - jeśli zadasz jakieś zapytanie SQL do instancji, owo zapytanie musi najpierw zostać sprawdzone pod kątem składniowym, również czy masz odpowiednie uprawnienia do odczytu/zapisu konkretnych danych. Oracle musi też wymyślić jak wykonać dane polecenie tak by zostało ono zakończone jak najszybciej. W tym celu wymyśla kilka planów wykonania zapytania, a następnie wybiera najbardziej optymalny.Gdyby Oracle za każdym razem miał wykonywać te same operacje dla tych samych zapytań byłaby to strata czasu. Dlatego wykonuje je za pierwszym razem, a następnie wrzuca właśnie do bufora bibliotecznego. Dzięki temu jeśli inny użytkownik wykona to samo zapytanie, Oracle sięgnie sobie do bufora bibliotecznego w którym już ma opracowany plan wykonania zapytania, sprawdzone czy zapytanie jest poprawne składniowo i nie musi tego wszystkiego wykonywać od początku.
Bufor słownika - w Oracle funkcjonują specjalne słowniki w których zapisane jest jakie w bazie znajdują się obiekty, jakie są pomiędzy nimi zależności i kto ma do nich uprawnienia. Do tych danych trzeba sięgać często, właściwie to przy każdym zapytaniu. Dlatego słowniki te są ładowane do pamięci, dzięki czemu jest do nich szybszy dostęp.
Ponadto w SGA znajdują się jeszcze inne bufory:
JAVA_POOL - czyli bufor służący do przechowywania kodu Java. W Oracle możemy przechowywać poza danymi również klasy Javy które w trakcie wykonania potrzebują pewnej przestrzeni pamięci - do tego służy właśnie bufor JAVA_POOL.
LARGE_POOL - Opcjonalny bufor który jest wykorzystywany przy okazji dużych operacji dyskowych np. backupu danych.
STREAMS_POOL - specjalny bufor wykorzystywany przy replikacji bazy danych.
Bufor danych domyślnie ma jedną część - DEFAULT. W razie potrzeby możemy jeszcze go podzielić na część KEEP, RECYCLE, oraz nK BUFFER.
Bufor KEEP -służy do przechowywania obiektów które chcemy trwale przechowywać w pamięci, w taki sposób by nie zostały "wypchnięte" przez nowe bloki danych. Przykładowo jeśli jakaś tabela jest wykorzystywana często, chcemy by zawsze był do niej szybki dostęp. W takim wypadku musimy stworzyć taki bufor i określić że ta tabela ma byc przechowywana w nim.
Bufor RECYCLE - do tego bufora możemy załadować obiekty z których korzystamy sporadycznie i nie chcemy by zajmowały nam cenne miejsce w buforze DEFAULT. Tu również musimy włączyć korzystanie z tego bufora i określić że dany obiekt ma być przechowywany właśnie w nim.
Bufor nK- Bufor do przechowywania obiektów o niestandardowej wielkości bloków. Nie będziemy się tym tutaj zajmować.
Obszar pamięci PGA
Ponieważ procesy serwera aby wykonać dla nas jakieś czynności też potrzebują pewnej ilości pamięci, alokowany jest dla każdego z nich obszar PGA. To specjalny wydzielony kawałek pamięci w którym proces serwera może :
- Sortować dane
- Trzymać informacje o sesji użytkownika
- Przechowywać informacje o zmiennych, tablicach, kursorach, danych przetwarzanych przez proces.
Oczywiście w momencie zakończenia sesji użytkownika bufor ten nie jest już potrzebny i zaalokowana dla niego pamięć jest zwalniana.
Procesy użytkowników i procesy serwera
Kiedy użytkownik łączy się do bazy danych, powstaje proces użytkownika. Standardowo dla każdego procesu użytkownika uruchamiany jest proces serwera. Proces serwera obsługuje żądania użytkowników po stronie instancji, takie jak odczyt i zapis danych. Sprawdza czy zapytania SQL generowane przez użytkownika są poprawne składniowo. Kontroluje również co się dzieje z sesją użytkownika - np. jeśli ten przerwie sesję, wszystkie jego transakcje (niezacommitowane) są automatycznie wycofywane.
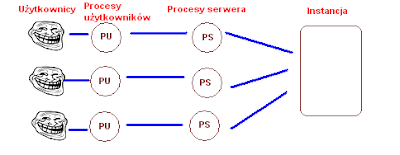
W pewnym sensie proces serwera jest przedstawicielem użytkownika po stronie instancji. To taki służący któremu mówimy przynieś to czy tamto, a on sam się znajduje znalezieniem tego czego potrzebujemy, ewentualnie sprząta ze stołu niedopitą przez nas kawę.
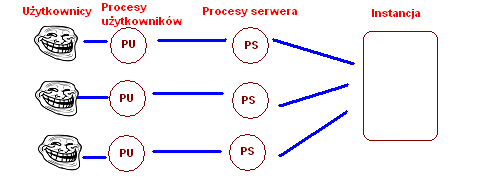
W pewnym sensie proces serwera jest przedstawicielem użytkownika po stronie instancji. To taki służący któremu mówimy przynieś to czy tamto, a on sam się znajduje znalezieniem tego czego potrzebujemy, ewentualnie sprząta ze stołu niedopitą przez nas kawę.
Baza danych a instancja
Jako admin powinieneś rozróżniać pojęcia instancja bazy danych i baza danych. Te dwie rzeczy często są ze sobą mylone.
Baza danych to zbiór plików fizycznie znajdujących się na dysku. Użytkownik nie może się podłączyć do bazy danych bezpośrednio. W połączeniu musi pośredniczyć instancja bazy danych która jest pewnego rodzaju tłumaczem pomiędzy nami użytkownikami a samym zbiorem danych.
Instancja bazy danych to zasadniczo uruchomiony program serwera, wraz z pamięcią przydzieloną do niego i procesami związanymi (działającymi w tle).

Baza danych to zbiór plików fizycznie znajdujących się na dysku. Użytkownik nie może się podłączyć do bazy danych bezpośrednio. W połączeniu musi pośredniczyć instancja bazy danych która jest pewnego rodzaju tłumaczem pomiędzy nami użytkownikami a samym zbiorem danych.
Instancja bazy danych to zasadniczo uruchomiony program serwera, wraz z pamięcią przydzieloną do niego i procesami związanymi (działającymi w tle).

Ustawienia startowe SQL*Plus
Korzystając z SQL*Plusa na pewno zauważyłeś, że ilekroć zamkniesz a następnie włączysz go znowu, wszystkie Twoje ustawienia dotyczące programu np. szerokość tekstu przywracane są do domyślnych.
Jest na to rada. Przejdź do katalogu oraclexe\app\oracle\product\10.2.0\server\sqlplus\admin
i edytuj znajdujący się w nim plik globin.sql
Ten plik zawiera opcje dotyczące ustawien SQL*Plusa i wczytywany jest w momencie podłączenia się do bazy.
Możesz tam wpisywać te opcje które do tej pory wpisywałeś w okienku np.
set linesize 120
Jest na to rada. Przejdź do katalogu oraclexe\app\oracle\product\10.2.0\server\sqlplus\admin
i edytuj znajdujący się w nim plik globin.sql
Ten plik zawiera opcje dotyczące ustawien SQL*Plusa i wczytywany jest w momencie podłączenia się do bazy.
Możesz tam wpisywać te opcje które do tej pory wpisywałeś w okienku np.
set linesize 120
SQL*Plus Komendy systemu operacyjnego
Przypadkiem znaleziony trick :)
Z poziomu SQL*Plusa możesz wykonywać komendy systemu operacyjnego!

Wystarczy że wpiszesz "host" a po nim w tej samej linii komendę. Na powyższym obrazku widać że z SQL*Plusa spingowałem onet.pl.
Wydaje się być przydatne, zwłaszcza jeśli jesteś podłączony po shellu do serwera i chcesz bez wychodzenia z SQL*Plusa coś sprawdzić.
Z poziomu SQL*Plusa możesz wykonywać komendy systemu operacyjnego!

Wystarczy że wpiszesz "host" a po nim w tej samej linii komendę. Na powyższym obrazku widać że z SQL*Plusa spingowałem onet.pl.
Wydaje się być przydatne, zwłaszcza jeśli jesteś podłączony po shellu do serwera i chcesz bez wychodzenia z SQL*Plusa coś sprawdzić.
piątek, 10 grudnia 2010
Wycinanie sesji użytkownika w Oracle
Czasem bywa tak, że któryś użytkownik nadmiernie obciąża nam system, jakieś zapytanie się zapętli, albo z różnych innych przyczyn chcemy rozłączyć użytkownika.
Do tego celu potrzebne nam będą informacje o SIDzie i SERIALu sesji usera którego chcemy wyciąć. Te informacje możemy uzyskać z dynamicznego słownika v$session:

Kodzik:
select * from v$session;
W tym słowniku mamy naprawdę sporo informacji o aktualnie podłączonych sesjach. Zaczynając od nazw podłączonych użyszkodników, przez nazwę hosta z którego jest podłączony aż po nazwę programu z jakiego korzysta skończywszy. Nas interesują dwie kolumny: SID oraz SERIAL#. Użytkownik którego chcę się pozbyć ma wartości odpowiednio 22,29. Mogę go teraz ubić na trzy różne sposoby:
ALTER SYSTEM KILL SESSION '22,29'
Najzwyczajniej w świecie ubija proces, wycofuje wszystkie transakcje. Od razu przerywa sesję użytkownika cokolwiek by ten nie robił. Kasuje też blokady na tabelach jeśli takowy użytkownik jakieś założył.
ALTER SYSTEM DISCONNECT SESSION '22,29' POST_TRANSACTION;
To jest takie delikatniejsze wypraszanie delikwenta. Pozwala mu zakończyć trwające transakcje, czeka na ROLLBACK lub COMMIT po czym mówi "dziękuję, dobranoc. Nie ma takiego łączenia!"
Jest jeszcze
ALTER SYSTEM DISCONNECT SESSION '22,29' IMMEDIATE;
który jest odpowiednikiem KILL SESSION, działa w sumie bardzo podobnie. Użyszkodnik dostaje trochę inny komunikat.
Do tego celu potrzebne nam będą informacje o SIDzie i SERIALu sesji usera którego chcemy wyciąć. Te informacje możemy uzyskać z dynamicznego słownika v$session:

Kodzik:
select * from v$session;
W tym słowniku mamy naprawdę sporo informacji o aktualnie podłączonych sesjach. Zaczynając od nazw podłączonych użyszkodników, przez nazwę hosta z którego jest podłączony aż po nazwę programu z jakiego korzysta skończywszy. Nas interesują dwie kolumny: SID oraz SERIAL#. Użytkownik którego chcę się pozbyć ma wartości odpowiednio 22,29. Mogę go teraz ubić na trzy różne sposoby:
ALTER SYSTEM KILL SESSION '22,29'
Najzwyczajniej w świecie ubija proces, wycofuje wszystkie transakcje. Od razu przerywa sesję użytkownika cokolwiek by ten nie robił. Kasuje też blokady na tabelach jeśli takowy użytkownik jakieś założył.
ALTER SYSTEM DISCONNECT SESSION '22,29' POST_TRANSACTION;
To jest takie delikatniejsze wypraszanie delikwenta. Pozwala mu zakończyć trwające transakcje, czeka na ROLLBACK lub COMMIT po czym mówi "dziękuję, dobranoc. Nie ma takiego łączenia!"
Jest jeszcze
ALTER SYSTEM DISCONNECT SESSION '22,29' IMMEDIATE;
który jest odpowiednikiem KILL SESSION, działa w sumie bardzo podobnie. Użyszkodnik dostaje trochę inny komunikat.
AUDIT czyli "Widzę Cię". Śledzenie działań użytkowników w Oracle.
Niekiedy zachodzi potrzeba obserwowania co się dzieje z obiektem w bazie danych. Przykładowo kto wrzuca dane, zmienia kluczowe wartości - my chcemy wiedzieć kto zmieniał np. tabelę i kiedy. Możemy też chcieć obserwować poczynania konkretnego użytkownika niezależnie od tego na jakich obiektach operuje. Do tego celu służy nam AUDIT.
Opcja monitoringu tego typu jest domyślnie wyłączona w Oracle. Musisz więc ją ustawić, a następnie zrestartować bazę.
Zaloguj się jako SYS a następnie wydaj polecenie :
alter system set audit_trail=true scope=spfile;
Ta komenda włącza opcję systemową audytu. Dodatek SCOPE = SPFILE na końcu oznacza że zmiany mają trafić do binarnego pliku parametrów bazy. Gdybyśmy tego nie dodali, system próbowałby wykonać to polecenie z domyślnym parametrem SCOPE=BOTH - czyli wrzucić do pliku parametrów oraz ustawić wartość dla sesji. Nie mógłby tego zrobić, ponieważ AUDIT_TRAIL nie jest parametrem który można zmieniać dynamicznie na włączonej bazie.
Jak już to włączysz zrestartuj bazę. Jako sys wykonaj SHUTDOWN IMMEDIATE (pamiętaj że ta opcja zerwie wszystkie sesje i wycofa transakcje. Miej to na uwadze jeśli koleżanka z działu obok wykonuje zapytanie trwające kilka godzin i lubi krzyczeć :) ).
Czas włączyć bazę. Zaloguj się jako sys do wyłączonej (!) bazy. Aby móc to zrobić, skorzystaj z SQL*Plusa i zaloguj się bez podawania "@adres_ip". Co za tym idzie-musisz zrobić to z komputera na którym stoi serwer Oracle (choćby przez shella). Jeśli wyłączałeś bazę z SQL*Plusa właśnie to nie musisz się przelogowywać.

Nie zapomnij o dodaniu "as sysdba" :).
Odpal bazę wpisując STARTUP;

Teraz masz już włączoną opcję audytu. Możesz się upewnić wywołując:
select * from v$parameter where name like '%trace_enabled%';
Śledzenie użytkownika
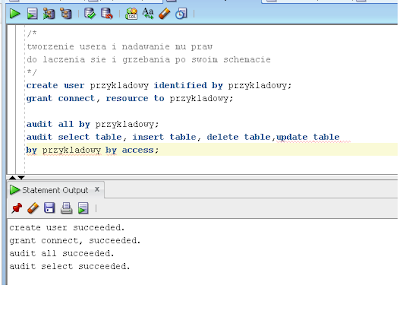
Dla przykładu stworzymy sobie jakiegoś użytkownika, zaczniemy go śledzić a następnie z jego poziomu wykonamy kilka czynności.
Stwórz użytkownika i nadaj mu uprawnienia do łączenia się do bazy danych i tworzenia obiektów w swoim
schemacie. Następnie włącz śledzenie użytkownika:



Opcja monitoringu tego typu jest domyślnie wyłączona w Oracle. Musisz więc ją ustawić, a następnie zrestartować bazę.
Zaloguj się jako SYS a następnie wydaj polecenie :
alter system set audit_trail=true scope=spfile;
Ta komenda włącza opcję systemową audytu. Dodatek SCOPE = SPFILE na końcu oznacza że zmiany mają trafić do binarnego pliku parametrów bazy. Gdybyśmy tego nie dodali, system próbowałby wykonać to polecenie z domyślnym parametrem SCOPE=BOTH - czyli wrzucić do pliku parametrów oraz ustawić wartość dla sesji. Nie mógłby tego zrobić, ponieważ AUDIT_TRAIL nie jest parametrem który można zmieniać dynamicznie na włączonej bazie.
Jak już to włączysz zrestartuj bazę. Jako sys wykonaj SHUTDOWN IMMEDIATE (pamiętaj że ta opcja zerwie wszystkie sesje i wycofa transakcje. Miej to na uwadze jeśli koleżanka z działu obok wykonuje zapytanie trwające kilka godzin i lubi krzyczeć :) ).
Czas włączyć bazę. Zaloguj się jako sys do wyłączonej (!) bazy. Aby móc to zrobić, skorzystaj z SQL*Plusa i zaloguj się bez podawania "@adres_ip". Co za tym idzie-musisz zrobić to z komputera na którym stoi serwer Oracle (choćby przez shella). Jeśli wyłączałeś bazę z SQL*Plusa właśnie to nie musisz się przelogowywać.

Nie zapomnij o dodaniu "as sysdba" :).
Odpal bazę wpisując STARTUP;

Teraz masz już włączoną opcję audytu. Możesz się upewnić wywołując:
select * from v$parameter where name like '%trace_enabled%';
Śledzenie użytkownika
Dla przykładu stworzymy sobie jakiegoś użytkownika, zaczniemy go śledzić a następnie z jego poziomu wykonamy kilka czynności.
Stwórz użytkownika i nadaj mu uprawnienia do łączenia się do bazy danych i tworzenia obiektów w swoim
schemacie. Następnie włącz śledzenie użytkownika:

Kodzik:
create user przykladowy identified by przykladowy;
grant connect, resource to przykladowy;
audit all by przykladowy;
audit select table, insert table, delete table,update table by przykladowy by access;
Możesz oczywiście wybrać które działania użytkownika chcesz monitorować. W tej drugiej linijce z audit wymieniasz wtedy tylko to co Cię interesuje.
Opcja BY ACCESS powoduje zachowanie informacji o działaniu użytkownika nawet jeśli już w ramach danej sesji wykonał instrukcję tego samego typu (np. więcej niż 1 raz wykonał selekta na jakiejś tabeli). Przeciwieństwem dla tej opcji jest BY SESSION, ale wtedy dany tym działania jest rejestrowany tylko raz.
Jeśli by zdarzyła się taka sytuacja, że rozpoczynasz śledzenie jakiegoś usera który już istnieje i do tego jest podłączony, to by śledzenie zaczęło działać musi się on przelogować lub musisz wymusić jego rozłączenie.
Zaloguj się teraz na tego nowego użytkownika. Wykonaj kilka operacji, najlepiej takich które chcesz śledzić :)

Kodzik:
create table produkty(
nr number,
nazwa varchar2(500),
cena number
);
insert into produkty values (1,'komputer',2500);
insert into produkty values (2,'telewizor',1800);
insert into produkty values (3,'pralka',1230);
insert into produkty values (4,'mikrofalówka',450);
update produkty set cena=320 where nr=4;
delete from produkty where nr=3;
select * from produkty;
Aby przejrzeć wyniki śledzenia wróć do użytkownika SYS. W Oracle jest tabelka dba_audit_trail która przechowuje wyniki śledzenia. Zadając do niej odpowiednie zapytanie, jesteś w stanie prześledzić działalność konkretnego użytkownika.
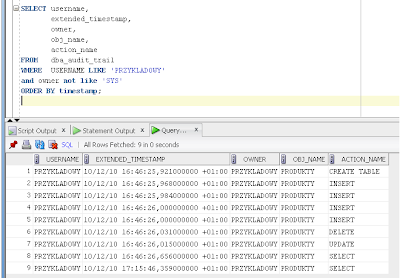
Kodzik:
SELECT username,
extended_timestamp,
owner,
obj_name,
action_name
FROM dba_audit_trail
WHERE USERNAME LIKE 'PRZYKLADOWY'
and owner not like 'SYS'
ORDER BY timestamp;
Ten warunek and owner not like 'SYS' jest po to by nie wyświetlać zmian w tabelach systemowych które wykonują się w związku z działalnością użytkownika.
Możesz też wyświetlić informacje na temat działań związanych z obiektami których właścicielem (twórcą) jest wybrany użytkownik:

Kodzik:
SELECT username,
extended_timestamp,
owner,
obj_name,
action_name
FROM dba_audit_trail
WHERE owner LIKE 'PRZYKLADOWY'
ORDER BY timestamp;
Wyświetliłem tylko kilka kolumn, bo tylko te nas właściwie interesują. W kolumnie USERNAME jest informacja kto wykonał dane działanie, w kolumnie OWNER na czyim obiekcie (tutaj akurat nasz user zmieniał dane we własnym obiekcie). OBJ_NAME zawiera informacje o nazwie obiektu na którym zostały wykonane działania a ACTION_NAME trzyma info o tym jaki typ działań został przez usera wykonany.
ZaCOMMITuj zmiany w tabeli którą utworzyłeś bo zaraz będziemy z tych zmian korzystać a chcemy mieć dostęp do danych dla innych użyszkodników.
Śledzenie działań na obiekcie
W tym przykładzie będziemy śledzić kto zmienia zawartość kontretnego obiektu, niezależnie od tego który to użyszkodnik.
Z poziomu SYSa wykonaj:
audit delete,insert,update on przykladowy.produkty by access;
Polecenie to włączy obserwację tabeli produkty w schemacie użytkownika przykładowy. Obserwowane będzie jedynie kasowanie, wrzucanie oraz zmiana danych w tej tabeli. Możesz oczywiście wymienić co chcesz, wybrać część z tych poleceń albo np. dodać select :)
Nadaj jeszcze uprawnienia użytkownikowi HR do wykonywania wszelakich działań na tabeli produkty użytkownika przykładowy:
grant all on przykladowy.produkty to hr;
Zaloguj się teraz jako user HR i dodaj jakieś dane, wykonaj selecta, zmień coś w tabeli produkty. Ja zrobiłem selecta i zmieniłem cenę jednego produktu:
select * from przykladowy.produkty;
update przykladowy.produkty set cena=1650 where nr=2;
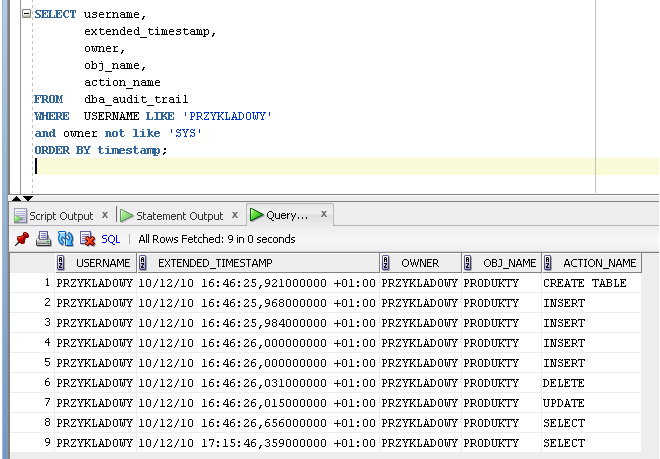
Trzeba trochę zmodyfikować nasze wcześniejsze zapytanie. W tym przypadku zmieniłem po prostu warunek where. Wyświetlam informacje o działaniach tylko te które mająw nazwie obiektu 'PRODUKTY' a więc nazwę tabeli która mnie interesuje.Dla wszelkiej pewności możesz dodać jeszcze warunek dla kolumny OWNER by mieć pewność że chodzi o tabelę konkretnego użytkownika. Tabela o takiej samej nazwie może występować przecież w kilku schematach.

Kodzik:
SELECT username,
extended_timestamp,
owner,
obj_name,
action_name
FROM dba_audit_trail
WHERE obj_name LIKE 'PRODUKTY'
ORDER BY timestamp;
środa, 8 grudnia 2010
Kurs administracji bazami danych Oracle - podstawy
Tutaj znajdzie się szybki kurs administracji serwerkiem Oracle. Część teoretyczną ograniczyłem do minimum po to, byście mogli szybko rozpocząć pracę z tymi zagadnieniami. Dlatego proszę, nie traktujcie mnie jak ignoranta. Umyślnie pominąłem spooooro rzeczy. Myślę że jeden weekend powinien Ci starczyć by pochłonąć ten kurs.
SZYBKIE WPROWADZENIE:
Podstawowe pojęcia
Architektura
SGA i PGA
Podstawowe narzędzia
Obiekty bazodanowe
Podstawowy flashback
Użytkownicy i uprawnienia
Profile
Audyt
Rozłączanie sesji
Włączanie i wyłączanie instancji
Backup i odtwarzanie
Eksport i import danych
Ustawienia sieciowe
GDY ZECHCESZ WIEDZIEĆ WIĘCEJ:
Duplikacja pliku kontrolnego , lub utrata jednego z kilku
RMAN - opcja CATALOG
Duplikacja bazy danych
Zapełnienie FRA
Flashback - tym razem na serio
Tryb flashback
Tryb flashback
Monitorowanie blokad
Tworzenie tablespace
Kontrola ilości połączeń
Partycjonowanie tabel
SQL Loader - czyli ładujemy CSV do bazy
Subskrybuj:
Posty (Atom)