Duplikacja jest kopią bazy z jednoczesną zmianą unikalnego identyfikatora bazy DBID. Możesz odtworzyć bazę danych na podstawie pliku backupu oraz archivelogów. Możliwa jest również duplikacja do punktu w czasie, dzięki czemu istnieje możliwość porównania aktualnego stanu obiektów (z bazy produkcyjnej) z ich stanem nawet w odległej przeszłości, gdy nie można już wykorzystać danych UNDO. Taka duplikacja do punktu w czasie działa podobnie jak odtwarzanie do punktu w czasie, z tym że na innej bazie docelowej. Duplikację możesz zastosować jako prostą metodę kopiowania bazy w celach testowych. Na takiej kopii możesz np. sprawdzić upgrady, patche, modyfikacje przed wdrożeniem zmian na bazie produkcyjnej. Bazę możesz zduplikować na tym samym hoście, lub po skopiowaniu niezbędnych plików na innym. Przedstawiony tutaj rodzaj duplikacji to w rzeczywistości odtworzenie bazy w innym miejscu na podstawie backupu.
Duplikacja 1-1
Metod na skopiowanie bazy jest kilka, tutaj prezentuję moim zdaniem najwygodniejszą tj. z wykorzystaniem katalogu. Potrzebujemy trzech połączeń. Do bazy źródłowej, do katalogu (który spełnia rolę repozytorium danych o backupach), oraz oczywiście do bazy docelowej. Ponadto z poziomu bazy docelowej musi być dostęp do plików backupów , oraz archivelogów bazy źródłowej. Jeśli duplifikujemy bazę na inny host, zapewnienie dostępu do backupów i archivelogów sprowadza się do ich skopiowania z serwera źródłowego do FRA na serwerze docelowym.
Całą operację przeprowadzamy z poziomu hosta docelowego, ponieważ baza docelowa przed duplikacją musi zostać uruchomiona do trybu NOMOUNT, nie będzie do niej dostepu poprzez Listener. Sama duplikacja po uprzednim przygotowaniu odpowiednich informacji i podłączeniu sprowadza się do wydania komendy „duplicate target database to nazwa_bazy_docelowej”. Ta komenda mimo że sprowadza się do paru słów, wywołuje w rzeczywistości skomplikowany mechanizm. Informacje które trzeba podać RMANowi przed duplikacją to nowa nazwa plików danych , oraz ewentualnie moment do którego odtwarzamy jeśli wykonujemy duplikację do punktu w czasie. Podać nowe nazwy plików można na dwa sposoby – albo pojedynczo dla każdego pliku danych, albo podając schemat zamiany nazw. W pierwszej kolejności wykorzystamy ten pierwszy sposób, mimo że jest bardziej czasochłonny, ale też łatwiejszy w zrozumieniu. Następnie powtórzymy operację z wykorzystaniem schematu zamiany nazw i ścieżek.
Przygotowania
Przede wszystkim potrzebujemy bazy , do której zostanie zduplifikowana nasza baza źródłowa. Uruchamiamy więc narzędzie DBCA i tworzymy bazę danych. Tworzenie bazy danych tym narzędziem jest na tyle proste, że nie będziemy się tym szczegółowo zajmować. Generalnie jest to „next, next, next, next , finish” :) Samo tworzenie bazy może chwilę potrwać.

Logujemy się do nowe bazy jako sys. Jest nam to potrzebne, bo przy duplikacji będzie trzeba podać nowe nazwy plików. Stosujemy najpierw tą pierwszą metodę. Gdybyśmy w ogóle nie zadbali o zmianę nazw plików danych, w czasie duplikacji dostalibyśmy komunikat o tym że istnieją już pliki o takiej nazwie , a sama duplikacja zostałaby przerwana. Określamy więc gdzie leżą nasze pliki danych i pliki tymczasowe.

Źródłowa baza danych musi pracować w trybie ARCHIVELOG, poza tym potrzebujemy przynajmniej jednego pełnego backupu który będzie podstawą do duplikacji. Na tym etapie powinieneś już wiedzieć jak włączyć tryb archivelog, jednak gdybyś zapomniał to przypominam :).
W pierwszej kolejności należy bazę położyć ( shutdown immediate ), następnie włączyć do trybu mount (startup mount), włączyć tryb archivelog (alter database archivelog ) i otworzyć (alter database open).
Po stworzeniu nowej bazy możesz natknąć się na niespodziewaną przeszkodę. DBCA po stworzeniu bazy ustawia nam w zmiennej systemowej ORACLE_SID sid nowej bazy danych. Konsekwencją tego jest fakt, że jeśli logujesz się do bazy sqlplusem bez podania sid'a (a tak się logujemy do wyłączonej ) to połączysz się do tej której SID jest ustawiony w zmiennej ORACLE_SID. Analogicznie przy podłączeniu za pomocą RMANa. Jeśli chcesz zmienić wartość tej zmiennej, w linuksie robisz to wydając komendę:
export ORACLE_SID=xxx
a w Windowsie :
set ORACLE_SID=xxx
gdzie xxx to sid bazy. Wielkość liter ma znaczenie.

Po ustawieniu ORACLE_SID na SID bazy źródłowej, wykonujemy jej pełną kopię zapasową (jeśli nie zrobiliśmy jej wcześniej). W przypadku gdybyś chciał zrobić duplikację pomiędzy różnymi hostami a wykonywałeś już jakieś backupy , to i tak warto wykonać ten jeden pełen backup. Dzięki temu będzie mniej niezbędnych plików do skopiowania, zwłaszcza archivelogów.

- Stwórz użytkownika i nadaj mu role: connect,resource, recovery_catalog_owner. Użytkownika stwórz na dowolnej bazie, byleby nie na tej bazie która będzie bazą docelową. Ważne byś do tej bazy mógł się później podłączyć z poziomu hosta na którym znajdzie się baza docelowa.

- Z poziomu RMANa podłącz się do bazy źródłowej oraz do schematu przed chwilą stworzonego użytkownika. Wydaj polecenia: „create catalog” oraz „register database”.
(więcej na ten temat znajdziesz w artykule „RMAN – opcja CATALOG” )

- Doprowadź teraz do tego by otwarte były bazy źródłowa oraz ta w której znajduje się katalog (u mnie to ta sama baza), natomiast baza docelowa była uruchomiona w trybie NOMOUNT. Musi być akurat NOMOUNT ponieważ podczas duplikacji będą zachodziły zmiany na jej pliku kontrolnym.

- Dalszą część czynności wykonujemy z poziomu hosta na którym znajduje się baza docelowa. Zadbaj teraz o to , by w zmiennej systemowej ORACLE_SID znalazł się sid bazy docelowej. Podłącz się teraz do bazy źródłowej , katalogu i bazy docelowej z poziomu rmana w taki sposób by:
Po connect target znajdowała się linijka połączenia do bazy źródłowej.
Po connect catalog znalazła się linijka połączenia do schematu w którym założyłeś katalog.
Po connect auxilary był slash (/) który spowoduje podłączenie do tej bazy której sid mamy w zmiennej systemowej ORACLE_SID.

Duplikacja
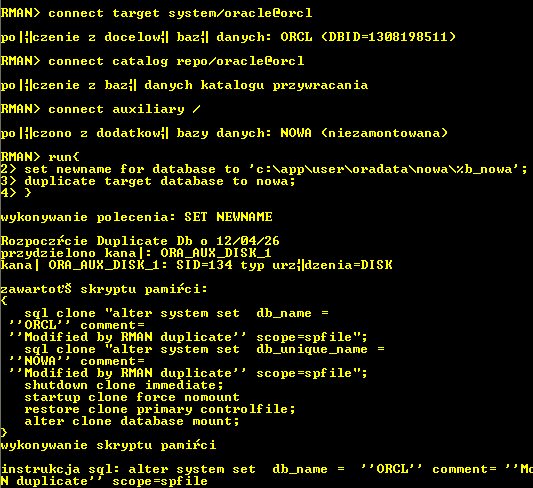
Przechodzimy do właściwej duplikacji. Wszystkie polecenia „set newname...” oraz ewentualnie
„set until time...” muszą znaleźć się w tym samym bloku run co polecenie „duplicate target database to ….”. Te polecenia obowiązują tylko w bloku RUN , więc nie możesz ich wykonywać niezależnie. Przy użyciu polecenia „set newname” nadajemy nazwy plikom danych które mają zostać utworzone w docelowej bazie danych wraz ze ścieżkami. Te numerki to numery plików danych w bazie źródłowej które wyświetlaliśmy na samym początku.

Komenda „duplicate target database to nowa” powoduje odtworzenie bazy źródłowej w bazie docelowej której sid podajemy (tutaj jest to „nowa”). Pamiętamy by ta komenda znalazła się w tym samym bloku run co wszystkie „set newname”. Do docelowej bazy danych zostanie odtworzony ostatni pełen backup bazy źródłowej, oraz wszystkie archivelogi jakie są dostępne.
Musimy teraz poczekać , proces duplikacji trwa przynajmniej tyle czasu ile pełne odtworzenie bazy źródłowej. Baza źródłowa po zakończeniu duplikacji zostanie otwarta.

Jeśli zechcemy odświeżyć naszą kopię bazy danych, wystarczy ponownie wykonać duplikację, tym razem jednak nie tworzymy nowej bazy :).
Troubleshot podczas duplikacji
Jeśli dopiero co włączyliśmy tryb archivelog w bazie źródłowej , może pojawić nam się taki bład:

Wynika on z tego, że nie zostały jeszcze utworzone żadne archivelogi. Wystarczy więc przełączyć pliki dziennika powtórzeń (w bazie źródłowej). Komunikat jest trochę mylący, chodzi o bazę źródłową – czyli tą którą kopiujemy a nie docelową – czyli tą do której kopiujemy. W nomenklaturze RMANa „baza docelowa” to ta do której jesteśmy podłączeni z użyciem klauzuli „target”. Przełączamy więc pliki dziennika powtórzeń:

a następnie powtarzamy próbe duplikacji.
Duplikacja do punktu w czasie
Podobnie jak możemy odtworzyć bazę do punktu w czasie , tak możemy również duplikować bazę do punktu w czasie. Ostatecznie duplikacja do punktu w czasie jest odtwarzaniem do punktu w czasie , tyle że innym miejscu. Wszystkie dotychczasowe kroki wykonujemy analogicznie, natomiast w samym bloku w którym wywołujemy duplikację dodajemy jeszcze komendę „set until time” korzystając ze znanej z SQLa funkcji to_date.

Schemat zmiany nazw plików danych i ścieżek do nich
Teraz czas na obiecaną krótszą wersję zmiany nazw plików przy duplikacji. Zamiast podawać nowe nazwy dla wszystkich plików danych osobno , możemy RMANowi wskazać schemat według którego ma je pozmieniać za nas. Zasady i procedury opisane wcześniej pozostają zasadniczo bez zmian, modyfikacja dotyczy tylko poleceń „set newname” już przy samej duplikacji. Zamiast set newname for datafile / tempfile piszemy tym razem set newname for database. Podajemy ścieżkę do katalogu w którym mają się znaleźć pliki danych oraz znacznik „%b” który oznacza starą nazwę pliku. Poniższa sekwencja spowoduje że powstaną pliki danych w katalogu którego ścieżkę podajemy, jednak będą nazywały się tak samo jak pliki danych w bazie źródłowej.
Możliwa jest też duplikacja do punktu w czasie z użyciem tej wygodniejszej formy zmiany nazw:














































