Jak już wiesz z poprzedniego rozdziału bufor danych domyślnie zawiera tylko część DEFAULT. Obiekty w nim się zawierające zostały załadowane tam w momencie kiedy zaszła konieczność sięgnięcia do nich z plików na dysku twardym. Na podstawie algorytmu LRU najdawniej używane obiekty zostają z tego bufora wywalane jeśli bufor się przepełni. Możesz jednak chcieć mieć jakiś obiekt zawsze przechowywany w pamięci bo mimo że sięgasz do niego rzadko, to jednak oczekujesz szybkiego dostępu do niego. Wpierw musisz ustawić sobie wielkość bufora keep :
alter system set db_keep_cache_size=10M;
Teraz możesz wybrane obiekty (tabele albo indeksy) zmienić tak by zawsze były one ładowane do bufora KEEP. Istniejącą tabelę możesz zmienić w ten sposób:
alter table tabela storage (buffer_pool keep);
Możesz również zdefiniować to od razu przy tworzeniu tabeli:
create table tabela2(
kolumna1 number,
kolumna2 varchar2(50)
)storage (buffer_pool keep);
sobota, 11 grudnia 2010
Konfiguracja parametrów SGA
 Zanim zaczniemy konfigurować sobie parametry SGA wypadałoby sprawdzić które z nich są zmienialne w ogóle i które jakie są ich aktualne wartości :)
Zanim zaczniemy konfigurować sobie parametry SGA wypadałoby sprawdzić które z nich są zmienialne w ogóle i które jakie są ich aktualne wartości :)Do sprawdzania obu tych rzeczy mamy specjalne słowniki:
- v$sgainfo - podstawowe informacje o wartościach i informacje czy dane parametr możemy dynamicznie zmieniać czy nie.
- v$sga_dynamic_components - tutaj są informacje znacznie szersze od sgainfo. Mamy też info o aktualnym wykorzystaniu buforów. Jednak nie ma informacji o tym czy dany parametr jest rozszerzalny czy nie.
Sprawdźmy aktualne ustawienia buforów:

Kodzik:
select * from v$sgainfo;
To jaki parametr ustawiamy na jaką wartość zależy od tego do czego nam będzie służyć baza i czego od niej oczekujemy.

Ostatnio bardzo się zdziwiłem kiedy zacząłem zmieniać różne parametry i ku memu wielkiemu zdziwieniu Oracle olewał to co mu ustawiałem. Ja mu ustawiam jakiś parametr a on mi swoje. Chłopaki z Oracla wpadli na przegenialny pomysł by te parametry ustawiały się same, obsrywając to co ustawia admin. To funkcjonuje od wersji 10 Oracle. Niestety nie byli na tyle sprytni by poinformować o tym fakcie jakimś ładnym komunikatem podczas próby ustawienia. Aby nasze zmiany odniosły jakikolwiek skutek musisz wyzerować parametr SGA_TARGET podłóg którego to pozostałe parametry ustawiają się same. SGA_TARGET określa docelową wielkość SGA (nie maksymalną) do jakiej Oracle ma dążyć. Przed ustawianiem czegokolwiek wykonaj więc:
alter system set sga_target=0;
Które to zeruje sga_target jednocześnie wyłączając automagiczne strojenie wielkości buforów. Dopiero teraz możesz zacząć ustawiać pozostałe parametry.
Swoją konfigurację najlepiej zacząć od ustawienia maksymalnej wartości SGA_MAX_SIZE który to parametr określa maksymalną wielkość SGA. Dlatego od tego zaczynamy, bo według tej wartości ustawia się inne parametry które to jako składowe SGA nie mogą sumarycznie przekroczyć jej wartości.
Parametru SGA_MAX_SIZE nie możemy modyfikować dynamicznie, musimy to ustawić w pliku konfiguracyjnym a następnie zrestartować instancję. Zmieniamy więc SGA_MAX_SIZE:
alter system set sga_max_size=700M scope=spfile;
700M to oczywiście 700 megabajtów. Możesz też dać K i wtedy będziesz mógł podać w kilobajtach. SCOPE=SPFILE oznacza że zmiana ma dotyczyć pliku konfiguracyjnego który czytany jest przy starcie instancji.
Zaloguj się jako sys przy użyciu sql plusa ( conn sys/haslo as sysdba ) Teraz zrestartuj instancję:

Kodzik:
Najpierw : SHUTDOWN IMMEDIATE;
Następnie: STARTUP;
Sprawdź aktualną wartość:

Mamy ustawione tak jak chcieliśmy - przy Maximum SGA Size widnieje ustawiona przez nas wartość. Jest ona podana w bajtach, a jak każdy wie 1 kB to 1024 B, a 1MB to 1024kB. Dlatego taka dziwna wartość.
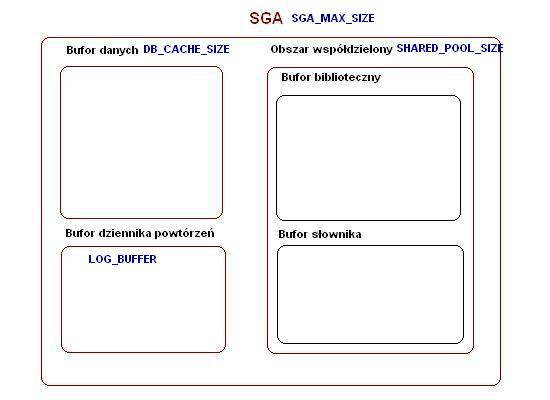
Teraz nazwy buforów i nazwy parametrów:
Bufor danych - DB_CACHE_SIZE
Obszar współdzielony - SHARED_POOL_SIZE
Bufor dziennika powtórzeń - LOG_BUFFER
Bufor Javy - JAVA_POOL_SIZE
Duży bufor - LARGE_POOL_SIZE
Bufor streams - STREAMS_POOL_SIZE
Ustawiam sobie konfigurację dla siebie. Nie będę korzystał z JAVY w Oracle, ani też raczej nie planuję na ten moment jakichś wielkich backupów. Za to oczekuję szybkiego działania bazy danych bez zbędnego oczekiwania na odczyt z dysku. Ustawiam sobie więc db_cache size na 500MB (by mieć dużo rzeczy pod ręką) , java_pool_size i large_pool_size ustawiam na bardzo małe wartości. Obszarowi współdzielonemu też rzucę te 100MB, niech zna łaskę Pana :) Przynajmniej będę miał zbuforowane poparsowane zapytania więc jak będzie mi śmigał duży system to zyskam na czasie parsowania SQLi.

Globalny obszar pamięci SGA
SGA (System Global Area) jest buforem pamięci alokowanym podczas startu instancji. Przechowuje informacje współdzielone przez różne procesy bazy danych. M.in przechowuje:

- Kopie danych z dysku (w buforze danych znajdującym się w SGA)
- Bufor dziennika powtórzeń
- Plany wykonania zapytań SQL
- ...
Generalnie wszystko to co jest potrzebne bazie danych do działania i musi być pod ręką (w pamięci dostępnej dla serwera).

Generalnie SGA dzieli się na kilka części.
Bufor danych - dane do których sięgamy zapytaniem, nie zawsze muszą być czytane z dysku. Jeśli ktoś wcześniej sięgał do danych których nie było w tym buforze, dane te musiały zostać odczytane z dysku a następnie wrzucone do bufora danych. Dzięki temu kiedy następna osoba zarząda tych samych danych, nie będzie już konieczności odczytywania ich z dysku bo będą dostępne w buforze danych. O tym że czas operacji odczytu z pamięci jest nieporównywalnie krótszy od czasu operacji odczytu z dysku jest nieporównywalnie krótszy, chyba nie muszę nikogo przekonywać :).
Działa to też w drugą stronę. Zmieniane czy dodawane dane też nie od razu pakowane są na dysk, są zmieniane najpierw w buforze danych, dzięki czemu są one szybciej dostępne. Oczywiście w pewnym momencie zapisuje je na dysk specjalny proces (DBWR) ale o tym nieco później.
Wiadomo że nie wszystkie dane mogą tu być przechowywane choćby ze względu na pojemność takiego bufora. Jeżeli bufor się przepełni, usuwane są dane najdawniej wykorzystywane. Jeżeli jakieś dane znajdujące się już w buforze zostaną wykorzystane ponownie, trafiają na początek listy. O to dba nam proces serwera. Takie działanie szumnie się nazywa algorytmem LRU (Last Recently Used)
Bufor dziennika powtórzeń - wszystkie zmiany danych są rejestrowane. Dzięki temu, nawet jeśli zmienione dane nie zostały jeszcze trwale zapisane na dysk, jesteśmy w stanie je odtworzyć. Istnieją specjalne pliki dziennika powtórzeń w których zapisywane są wszelkie zmiany, jednak informacja zanim tam trafi, trafia do bufora dziennika powtórzeń.
Bufor biblioteczny - jeśli zadasz jakieś zapytanie SQL do instancji, owo zapytanie musi najpierw zostać sprawdzone pod kątem składniowym, również czy masz odpowiednie uprawnienia do odczytu/zapisu konkretnych danych. Oracle musi też wymyślić jak wykonać dane polecenie tak by zostało ono zakończone jak najszybciej. W tym celu wymyśla kilka planów wykonania zapytania, a następnie wybiera najbardziej optymalny.Gdyby Oracle za każdym razem miał wykonywać te same operacje dla tych samych zapytań byłaby to strata czasu. Dlatego wykonuje je za pierwszym razem, a następnie wrzuca właśnie do bufora bibliotecznego. Dzięki temu jeśli inny użytkownik wykona to samo zapytanie, Oracle sięgnie sobie do bufora bibliotecznego w którym już ma opracowany plan wykonania zapytania, sprawdzone czy zapytanie jest poprawne składniowo i nie musi tego wszystkiego wykonywać od początku.
Bufor słownika - w Oracle funkcjonują specjalne słowniki w których zapisane jest jakie w bazie znajdują się obiekty, jakie są pomiędzy nimi zależności i kto ma do nich uprawnienia. Do tych danych trzeba sięgać często, właściwie to przy każdym zapytaniu. Dlatego słowniki te są ładowane do pamięci, dzięki czemu jest do nich szybszy dostęp.
Ponadto w SGA znajdują się jeszcze inne bufory:
JAVA_POOL - czyli bufor służący do przechowywania kodu Java. W Oracle możemy przechowywać poza danymi również klasy Javy które w trakcie wykonania potrzebują pewnej przestrzeni pamięci - do tego służy właśnie bufor JAVA_POOL.
LARGE_POOL - Opcjonalny bufor który jest wykorzystywany przy okazji dużych operacji dyskowych np. backupu danych.
STREAMS_POOL - specjalny bufor wykorzystywany przy replikacji bazy danych.
Bufor danych domyślnie ma jedną część - DEFAULT. W razie potrzeby możemy jeszcze go podzielić na część KEEP, RECYCLE, oraz nK BUFFER.
Bufor KEEP -służy do przechowywania obiektów które chcemy trwale przechowywać w pamięci, w taki sposób by nie zostały "wypchnięte" przez nowe bloki danych. Przykładowo jeśli jakaś tabela jest wykorzystywana często, chcemy by zawsze był do niej szybki dostęp. W takim wypadku musimy stworzyć taki bufor i określić że ta tabela ma byc przechowywana w nim.
Bufor RECYCLE - do tego bufora możemy załadować obiekty z których korzystamy sporadycznie i nie chcemy by zajmowały nam cenne miejsce w buforze DEFAULT. Tu również musimy włączyć korzystanie z tego bufora i określić że dany obiekt ma być przechowywany właśnie w nim.
Bufor nK- Bufor do przechowywania obiektów o niestandardowej wielkości bloków. Nie będziemy się tym tutaj zajmować.
Obszar pamięci PGA
Ponieważ procesy serwera aby wykonać dla nas jakieś czynności też potrzebują pewnej ilości pamięci, alokowany jest dla każdego z nich obszar PGA. To specjalny wydzielony kawałek pamięci w którym proces serwera może :
- Sortować dane
- Trzymać informacje o sesji użytkownika
- Przechowywać informacje o zmiennych, tablicach, kursorach, danych przetwarzanych przez proces.
Oczywiście w momencie zakończenia sesji użytkownika bufor ten nie jest już potrzebny i zaalokowana dla niego pamięć jest zwalniana.
Procesy użytkowników i procesy serwera
Kiedy użytkownik łączy się do bazy danych, powstaje proces użytkownika. Standardowo dla każdego procesu użytkownika uruchamiany jest proces serwera. Proces serwera obsługuje żądania użytkowników po stronie instancji, takie jak odczyt i zapis danych. Sprawdza czy zapytania SQL generowane przez użytkownika są poprawne składniowo. Kontroluje również co się dzieje z sesją użytkownika - np. jeśli ten przerwie sesję, wszystkie jego transakcje (niezacommitowane) są automatycznie wycofywane.
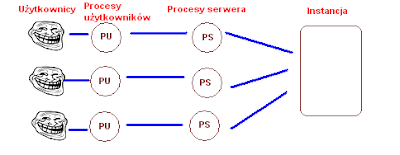
W pewnym sensie proces serwera jest przedstawicielem użytkownika po stronie instancji. To taki służący któremu mówimy przynieś to czy tamto, a on sam się znajduje znalezieniem tego czego potrzebujemy, ewentualnie sprząta ze stołu niedopitą przez nas kawę.
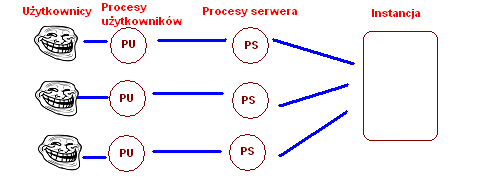
W pewnym sensie proces serwera jest przedstawicielem użytkownika po stronie instancji. To taki służący któremu mówimy przynieś to czy tamto, a on sam się znajduje znalezieniem tego czego potrzebujemy, ewentualnie sprząta ze stołu niedopitą przez nas kawę.
Baza danych a instancja
Jako admin powinieneś rozróżniać pojęcia instancja bazy danych i baza danych. Te dwie rzeczy często są ze sobą mylone.
Baza danych to zbiór plików fizycznie znajdujących się na dysku. Użytkownik nie może się podłączyć do bazy danych bezpośrednio. W połączeniu musi pośredniczyć instancja bazy danych która jest pewnego rodzaju tłumaczem pomiędzy nami użytkownikami a samym zbiorem danych.
Instancja bazy danych to zasadniczo uruchomiony program serwera, wraz z pamięcią przydzieloną do niego i procesami związanymi (działającymi w tle).

Baza danych to zbiór plików fizycznie znajdujących się na dysku. Użytkownik nie może się podłączyć do bazy danych bezpośrednio. W połączeniu musi pośredniczyć instancja bazy danych która jest pewnego rodzaju tłumaczem pomiędzy nami użytkownikami a samym zbiorem danych.
Instancja bazy danych to zasadniczo uruchomiony program serwera, wraz z pamięcią przydzieloną do niego i procesami związanymi (działającymi w tle).

Ustawienia startowe SQL*Plus
Korzystając z SQL*Plusa na pewno zauważyłeś, że ilekroć zamkniesz a następnie włączysz go znowu, wszystkie Twoje ustawienia dotyczące programu np. szerokość tekstu przywracane są do domyślnych.
Jest na to rada. Przejdź do katalogu oraclexe\app\oracle\product\10.2.0\server\sqlplus\admin
i edytuj znajdujący się w nim plik globin.sql
Ten plik zawiera opcje dotyczące ustawien SQL*Plusa i wczytywany jest w momencie podłączenia się do bazy.
Możesz tam wpisywać te opcje które do tej pory wpisywałeś w okienku np.
set linesize 120
Jest na to rada. Przejdź do katalogu oraclexe\app\oracle\product\10.2.0\server\sqlplus\admin
i edytuj znajdujący się w nim plik globin.sql
Ten plik zawiera opcje dotyczące ustawien SQL*Plusa i wczytywany jest w momencie podłączenia się do bazy.
Możesz tam wpisywać te opcje które do tej pory wpisywałeś w okienku np.
set linesize 120
SQL*Plus Komendy systemu operacyjnego
Przypadkiem znaleziony trick :)
Z poziomu SQL*Plusa możesz wykonywać komendy systemu operacyjnego!

Wystarczy że wpiszesz "host" a po nim w tej samej linii komendę. Na powyższym obrazku widać że z SQL*Plusa spingowałem onet.pl.
Wydaje się być przydatne, zwłaszcza jeśli jesteś podłączony po shellu do serwera i chcesz bez wychodzenia z SQL*Plusa coś sprawdzić.
Z poziomu SQL*Plusa możesz wykonywać komendy systemu operacyjnego!

Wystarczy że wpiszesz "host" a po nim w tej samej linii komendę. Na powyższym obrazku widać że z SQL*Plusa spingowałem onet.pl.
Wydaje się być przydatne, zwłaszcza jeśli jesteś podłączony po shellu do serwera i chcesz bez wychodzenia z SQL*Plusa coś sprawdzić.
piątek, 10 grudnia 2010
Wycinanie sesji użytkownika w Oracle
Czasem bywa tak, że któryś użytkownik nadmiernie obciąża nam system, jakieś zapytanie się zapętli, albo z różnych innych przyczyn chcemy rozłączyć użytkownika.
Do tego celu potrzebne nam będą informacje o SIDzie i SERIALu sesji usera którego chcemy wyciąć. Te informacje możemy uzyskać z dynamicznego słownika v$session:

Kodzik:
select * from v$session;
W tym słowniku mamy naprawdę sporo informacji o aktualnie podłączonych sesjach. Zaczynając od nazw podłączonych użyszkodników, przez nazwę hosta z którego jest podłączony aż po nazwę programu z jakiego korzysta skończywszy. Nas interesują dwie kolumny: SID oraz SERIAL#. Użytkownik którego chcę się pozbyć ma wartości odpowiednio 22,29. Mogę go teraz ubić na trzy różne sposoby:
ALTER SYSTEM KILL SESSION '22,29'
Najzwyczajniej w świecie ubija proces, wycofuje wszystkie transakcje. Od razu przerywa sesję użytkownika cokolwiek by ten nie robił. Kasuje też blokady na tabelach jeśli takowy użytkownik jakieś założył.
ALTER SYSTEM DISCONNECT SESSION '22,29' POST_TRANSACTION;
To jest takie delikatniejsze wypraszanie delikwenta. Pozwala mu zakończyć trwające transakcje, czeka na ROLLBACK lub COMMIT po czym mówi "dziękuję, dobranoc. Nie ma takiego łączenia!"
Jest jeszcze
ALTER SYSTEM DISCONNECT SESSION '22,29' IMMEDIATE;
który jest odpowiednikiem KILL SESSION, działa w sumie bardzo podobnie. Użyszkodnik dostaje trochę inny komunikat.
Do tego celu potrzebne nam będą informacje o SIDzie i SERIALu sesji usera którego chcemy wyciąć. Te informacje możemy uzyskać z dynamicznego słownika v$session:

Kodzik:
select * from v$session;
W tym słowniku mamy naprawdę sporo informacji o aktualnie podłączonych sesjach. Zaczynając od nazw podłączonych użyszkodników, przez nazwę hosta z którego jest podłączony aż po nazwę programu z jakiego korzysta skończywszy. Nas interesują dwie kolumny: SID oraz SERIAL#. Użytkownik którego chcę się pozbyć ma wartości odpowiednio 22,29. Mogę go teraz ubić na trzy różne sposoby:
ALTER SYSTEM KILL SESSION '22,29'
Najzwyczajniej w świecie ubija proces, wycofuje wszystkie transakcje. Od razu przerywa sesję użytkownika cokolwiek by ten nie robił. Kasuje też blokady na tabelach jeśli takowy użytkownik jakieś założył.
ALTER SYSTEM DISCONNECT SESSION '22,29' POST_TRANSACTION;
To jest takie delikatniejsze wypraszanie delikwenta. Pozwala mu zakończyć trwające transakcje, czeka na ROLLBACK lub COMMIT po czym mówi "dziękuję, dobranoc. Nie ma takiego łączenia!"
Jest jeszcze
ALTER SYSTEM DISCONNECT SESSION '22,29' IMMEDIATE;
który jest odpowiednikiem KILL SESSION, działa w sumie bardzo podobnie. Użyszkodnik dostaje trochę inny komunikat.
AUDIT czyli "Widzę Cię". Śledzenie działań użytkowników w Oracle.
Niekiedy zachodzi potrzeba obserwowania co się dzieje z obiektem w bazie danych. Przykładowo kto wrzuca dane, zmienia kluczowe wartości - my chcemy wiedzieć kto zmieniał np. tabelę i kiedy. Możemy też chcieć obserwować poczynania konkretnego użytkownika niezależnie od tego na jakich obiektach operuje. Do tego celu służy nam AUDIT.
Opcja monitoringu tego typu jest domyślnie wyłączona w Oracle. Musisz więc ją ustawić, a następnie zrestartować bazę.
Zaloguj się jako SYS a następnie wydaj polecenie :
alter system set audit_trail=true scope=spfile;
Ta komenda włącza opcję systemową audytu. Dodatek SCOPE = SPFILE na końcu oznacza że zmiany mają trafić do binarnego pliku parametrów bazy. Gdybyśmy tego nie dodali, system próbowałby wykonać to polecenie z domyślnym parametrem SCOPE=BOTH - czyli wrzucić do pliku parametrów oraz ustawić wartość dla sesji. Nie mógłby tego zrobić, ponieważ AUDIT_TRAIL nie jest parametrem który można zmieniać dynamicznie na włączonej bazie.
Jak już to włączysz zrestartuj bazę. Jako sys wykonaj SHUTDOWN IMMEDIATE (pamiętaj że ta opcja zerwie wszystkie sesje i wycofa transakcje. Miej to na uwadze jeśli koleżanka z działu obok wykonuje zapytanie trwające kilka godzin i lubi krzyczeć :) ).
Czas włączyć bazę. Zaloguj się jako sys do wyłączonej (!) bazy. Aby móc to zrobić, skorzystaj z SQL*Plusa i zaloguj się bez podawania "@adres_ip". Co za tym idzie-musisz zrobić to z komputera na którym stoi serwer Oracle (choćby przez shella). Jeśli wyłączałeś bazę z SQL*Plusa właśnie to nie musisz się przelogowywać.

Nie zapomnij o dodaniu "as sysdba" :).
Odpal bazę wpisując STARTUP;

Teraz masz już włączoną opcję audytu. Możesz się upewnić wywołując:
select * from v$parameter where name like '%trace_enabled%';
Śledzenie użytkownika
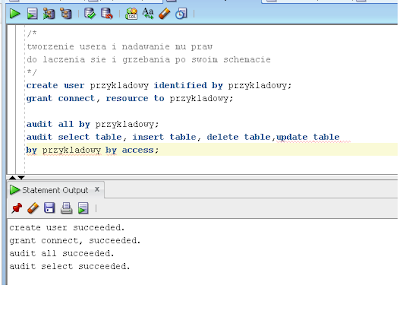
Dla przykładu stworzymy sobie jakiegoś użytkownika, zaczniemy go śledzić a następnie z jego poziomu wykonamy kilka czynności.
Stwórz użytkownika i nadaj mu uprawnienia do łączenia się do bazy danych i tworzenia obiektów w swoim
schemacie. Następnie włącz śledzenie użytkownika:



Opcja monitoringu tego typu jest domyślnie wyłączona w Oracle. Musisz więc ją ustawić, a następnie zrestartować bazę.
Zaloguj się jako SYS a następnie wydaj polecenie :
alter system set audit_trail=true scope=spfile;
Ta komenda włącza opcję systemową audytu. Dodatek SCOPE = SPFILE na końcu oznacza że zmiany mają trafić do binarnego pliku parametrów bazy. Gdybyśmy tego nie dodali, system próbowałby wykonać to polecenie z domyślnym parametrem SCOPE=BOTH - czyli wrzucić do pliku parametrów oraz ustawić wartość dla sesji. Nie mógłby tego zrobić, ponieważ AUDIT_TRAIL nie jest parametrem który można zmieniać dynamicznie na włączonej bazie.
Jak już to włączysz zrestartuj bazę. Jako sys wykonaj SHUTDOWN IMMEDIATE (pamiętaj że ta opcja zerwie wszystkie sesje i wycofa transakcje. Miej to na uwadze jeśli koleżanka z działu obok wykonuje zapytanie trwające kilka godzin i lubi krzyczeć :) ).
Czas włączyć bazę. Zaloguj się jako sys do wyłączonej (!) bazy. Aby móc to zrobić, skorzystaj z SQL*Plusa i zaloguj się bez podawania "@adres_ip". Co za tym idzie-musisz zrobić to z komputera na którym stoi serwer Oracle (choćby przez shella). Jeśli wyłączałeś bazę z SQL*Plusa właśnie to nie musisz się przelogowywać.

Nie zapomnij o dodaniu "as sysdba" :).
Odpal bazę wpisując STARTUP;

Teraz masz już włączoną opcję audytu. Możesz się upewnić wywołując:
select * from v$parameter where name like '%trace_enabled%';
Śledzenie użytkownika
Dla przykładu stworzymy sobie jakiegoś użytkownika, zaczniemy go śledzić a następnie z jego poziomu wykonamy kilka czynności.
Stwórz użytkownika i nadaj mu uprawnienia do łączenia się do bazy danych i tworzenia obiektów w swoim
schemacie. Następnie włącz śledzenie użytkownika:

Kodzik:
create user przykladowy identified by przykladowy;
grant connect, resource to przykladowy;
audit all by przykladowy;
audit select table, insert table, delete table,update table by przykladowy by access;
Możesz oczywiście wybrać które działania użytkownika chcesz monitorować. W tej drugiej linijce z audit wymieniasz wtedy tylko to co Cię interesuje.
Opcja BY ACCESS powoduje zachowanie informacji o działaniu użytkownika nawet jeśli już w ramach danej sesji wykonał instrukcję tego samego typu (np. więcej niż 1 raz wykonał selekta na jakiejś tabeli). Przeciwieństwem dla tej opcji jest BY SESSION, ale wtedy dany tym działania jest rejestrowany tylko raz.
Jeśli by zdarzyła się taka sytuacja, że rozpoczynasz śledzenie jakiegoś usera który już istnieje i do tego jest podłączony, to by śledzenie zaczęło działać musi się on przelogować lub musisz wymusić jego rozłączenie.
Zaloguj się teraz na tego nowego użytkownika. Wykonaj kilka operacji, najlepiej takich które chcesz śledzić :)

Kodzik:
create table produkty(
nr number,
nazwa varchar2(500),
cena number
);
insert into produkty values (1,'komputer',2500);
insert into produkty values (2,'telewizor',1800);
insert into produkty values (3,'pralka',1230);
insert into produkty values (4,'mikrofalówka',450);
update produkty set cena=320 where nr=4;
delete from produkty where nr=3;
select * from produkty;
Aby przejrzeć wyniki śledzenia wróć do użytkownika SYS. W Oracle jest tabelka dba_audit_trail która przechowuje wyniki śledzenia. Zadając do niej odpowiednie zapytanie, jesteś w stanie prześledzić działalność konkretnego użytkownika.
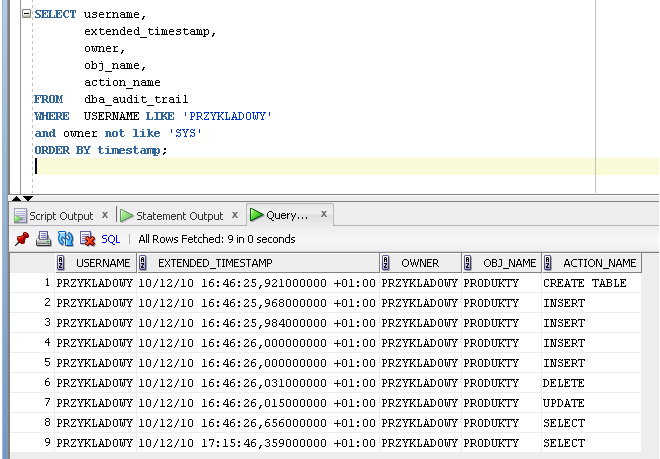
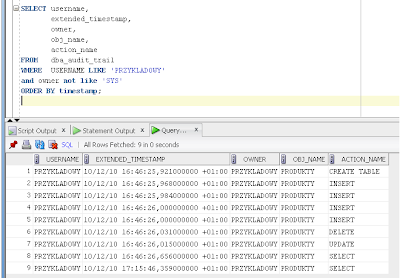
Kodzik:
SELECT username,
extended_timestamp,
owner,
obj_name,
action_name
FROM dba_audit_trail
WHERE USERNAME LIKE 'PRZYKLADOWY'
and owner not like 'SYS'
ORDER BY timestamp;
Ten warunek and owner not like 'SYS' jest po to by nie wyświetlać zmian w tabelach systemowych które wykonują się w związku z działalnością użytkownika.
Możesz też wyświetlić informacje na temat działań związanych z obiektami których właścicielem (twórcą) jest wybrany użytkownik:

Kodzik:
SELECT username,
extended_timestamp,
owner,
obj_name,
action_name
FROM dba_audit_trail
WHERE owner LIKE 'PRZYKLADOWY'
ORDER BY timestamp;
Wyświetliłem tylko kilka kolumn, bo tylko te nas właściwie interesują. W kolumnie USERNAME jest informacja kto wykonał dane działanie, w kolumnie OWNER na czyim obiekcie (tutaj akurat nasz user zmieniał dane we własnym obiekcie). OBJ_NAME zawiera informacje o nazwie obiektu na którym zostały wykonane działania a ACTION_NAME trzyma info o tym jaki typ działań został przez usera wykonany.
ZaCOMMITuj zmiany w tabeli którą utworzyłeś bo zaraz będziemy z tych zmian korzystać a chcemy mieć dostęp do danych dla innych użyszkodników.
Śledzenie działań na obiekcie
W tym przykładzie będziemy śledzić kto zmienia zawartość kontretnego obiektu, niezależnie od tego który to użyszkodnik.
Z poziomu SYSa wykonaj:
audit delete,insert,update on przykladowy.produkty by access;
Polecenie to włączy obserwację tabeli produkty w schemacie użytkownika przykładowy. Obserwowane będzie jedynie kasowanie, wrzucanie oraz zmiana danych w tej tabeli. Możesz oczywiście wymienić co chcesz, wybrać część z tych poleceń albo np. dodać select :)
Nadaj jeszcze uprawnienia użytkownikowi HR do wykonywania wszelakich działań na tabeli produkty użytkownika przykładowy:
grant all on przykladowy.produkty to hr;
Zaloguj się teraz jako user HR i dodaj jakieś dane, wykonaj selecta, zmień coś w tabeli produkty. Ja zrobiłem selecta i zmieniłem cenę jednego produktu:
select * from przykladowy.produkty;
update przykladowy.produkty set cena=1650 where nr=2;
Trzeba trochę zmodyfikować nasze wcześniejsze zapytanie. W tym przypadku zmieniłem po prostu warunek where. Wyświetlam informacje o działaniach tylko te które mająw nazwie obiektu 'PRODUKTY' a więc nazwę tabeli która mnie interesuje.Dla wszelkiej pewności możesz dodać jeszcze warunek dla kolumny OWNER by mieć pewność że chodzi o tabelę konkretnego użytkownika. Tabela o takiej samej nazwie może występować przecież w kilku schematach.

Kodzik:
SELECT username,
extended_timestamp,
owner,
obj_name,
action_name
FROM dba_audit_trail
WHERE obj_name LIKE 'PRODUKTY'
ORDER BY timestamp;
środa, 8 grudnia 2010
Kurs administracji bazami danych Oracle - podstawy
Tutaj znajdzie się szybki kurs administracji serwerkiem Oracle. Część teoretyczną ograniczyłem do minimum po to, byście mogli szybko rozpocząć pracę z tymi zagadnieniami. Dlatego proszę, nie traktujcie mnie jak ignoranta. Umyślnie pominąłem spooooro rzeczy. Myślę że jeden weekend powinien Ci starczyć by pochłonąć ten kurs.
SZYBKIE WPROWADZENIE:
Podstawowe pojęcia
Architektura
SGA i PGA
Podstawowe narzędzia
Obiekty bazodanowe
Podstawowy flashback
Użytkownicy i uprawnienia
Profile
Audyt
Rozłączanie sesji
Włączanie i wyłączanie instancji
Backup i odtwarzanie
Eksport i import danych
Ustawienia sieciowe
GDY ZECHCESZ WIEDZIEĆ WIĘCEJ:
Duplikacja pliku kontrolnego , lub utrata jednego z kilku
RMAN - opcja CATALOG
Duplikacja bazy danych
Zapełnienie FRA
Flashback - tym razem na serio
Tryb flashback
Tryb flashback
Monitorowanie blokad
Tworzenie tablespace
Kontrola ilości połączeń
Partycjonowanie tabel
SQL Loader - czyli ładujemy CSV do bazy
niedziela, 28 listopada 2010
Zaglądamy w przeszłość :) Czyli odzyskiwanie utraconych danych dla NIE-adminów
Pewnie drogi czytelniku zdarzyło Ci się już nie raz pomylić się przy jakimś update i chciałbyś cofnąć zmiany. Jeśli nie masz włączonego autocommita to żaden problem zrobić ROLLBACK. Co jednak jeśli zacommitowałeś sam albo miałeś włączonego autocommita i dopiero po kilku innych zmianach ogarnąłeś się że coś jest nie tak?
Telefon do admina i przywracanie z backupu? Nie zawsze jest to konieczne. Jak to mówi Czesio z "Włatcóf muh" - teraz będzie sztuczka magiczka :).
Robimy! Zrób sobie kopię tabeli employees albo jakiejś innej. Sprawdzam i widzę że są jakieś dane.


Idź po kawę. Symulujemy poranne zamulenie, czyli udajemy że cośtam robisz i dopiero za moment się połapiesz że zwaliłeś akcję. Jak chcesz to możesz jeszcze sobie coś pododawać do tabeli, pozmieniać i pokasować dodane dane. Tak dla mocniejszego efektu dzieła zniszczenia.
Minęło już trochę?
To właśnie się połapaliśmy że nabroiliśmy. Wiemy że tabelka zawierała jeszcze poprawne dane jakieś 10 minut temu. "Chciałbym się cofnąć w czasie o te 10 minut".... No to się cofnij! :

Kodzik:
SELECT * FROM WYPADEK
as of timestamp ( to_timestamp('12:38:00 2010-11-28','hh24:mi:ss yyyy-mm-dd') );
Tylko oczywiście zmień sobie datę i czas na swoje :) Dodanie klauzuli as of timestamp spowodowało wyświetlenie całej zawartości tabeli WYPADEK takiej jaka była we wskazanym czasie. Funkcja to_timestamp zwraca nam dane typu timestamp z tekstu. Drugi parametr to wzorzec. Przyjmuje takie same znaczniki jak funkcja to_date. Przyjmuje datę w postaci tekstu, zamienia wg. wzorca na format daty.
Możesz teraz przenieść sobie te dane do jakiejś innej tabeli:
CREATE TABLE WYPADEK2 AS SELECT * FROM WYPADEK WHERE 1=2;
INSERT INTO WYPADEK2 SELECT * FROM WYPADEK
as of timestamp ( to_timestamp('12:38:00 2010-11-28','hh24:mi:ss yyyy-mm-dd') );
Tadam!
Telefon do admina i przywracanie z backupu? Nie zawsze jest to konieczne. Jak to mówi Czesio z "Włatcóf muh" - teraz będzie sztuczka magiczka :).
Robimy! Zrób sobie kopię tabeli employees albo jakiejś innej. Sprawdzam i widzę że są jakieś dane.

Spójrz na zegarek. U mnie jest 12:38. To jest czas kiedy z tabelą jest jeszcze wszystko w porządku. Tzn - jeszcze przed moimi niecnymi działaniami. Poczekaj parę chwil - tak ze dwie minuty, żeby nam się czas chociaż o minutę zmienił.
To teraz robimy problemy. Kasujemy wszystko z tabeli i commitujemy.

Idź po kawę. Symulujemy poranne zamulenie, czyli udajemy że cośtam robisz i dopiero za moment się połapiesz że zwaliłeś akcję. Jak chcesz to możesz jeszcze sobie coś pododawać do tabeli, pozmieniać i pokasować dodane dane. Tak dla mocniejszego efektu dzieła zniszczenia.
Minęło już trochę?
To właśnie się połapaliśmy że nabroiliśmy. Wiemy że tabelka zawierała jeszcze poprawne dane jakieś 10 minut temu. "Chciałbym się cofnąć w czasie o te 10 minut".... No to się cofnij! :

Kodzik:
SELECT * FROM WYPADEK
as of timestamp ( to_timestamp('12:38:00 2010-11-28','hh24:mi:ss yyyy-mm-dd') );
Tylko oczywiście zmień sobie datę i czas na swoje :) Dodanie klauzuli as of timestamp spowodowało wyświetlenie całej zawartości tabeli WYPADEK takiej jaka była we wskazanym czasie. Funkcja to_timestamp zwraca nam dane typu timestamp z tekstu. Drugi parametr to wzorzec. Przyjmuje takie same znaczniki jak funkcja to_date. Przyjmuje datę w postaci tekstu, zamienia wg. wzorca na format daty.
Możesz teraz przenieść sobie te dane do jakiejś innej tabeli:
CREATE TABLE WYPADEK2 AS SELECT * FROM WYPADEK WHERE 1=2;
INSERT INTO WYPADEK2 SELECT * FROM WYPADEK
as of timestamp ( to_timestamp('12:38:00 2010-11-28','hh24:mi:ss yyyy-mm-dd') );
Tadam!
sobota, 27 listopada 2010
Select po pliku tekstowym
Dobry trick przy maści wszelkiej integracji systemów. Przypuśćmy że jeden system ma gdzieś tam na dysku pliki CSV, aktualizuje je regularnie. Może być też tak że taki plik jest często eksportowany z innego miejsca, a my chcemy być z danymi zawartymi w tym pliku na bieżąco. Regularne importy nawet przy użyciu CRONa są nieco workaroundem bo przecież dane mogą się zmieniać co parę sekund, a poza tym import to spore obciążenie dla systemu.
W Oracle jest opcja stworzenia specjalnej tabeli będącej niejako nakładką na plik tekstowy. Sprawia ona że możemy korzystać z danych w pliku tekstowym prawie w taki sam sposób jakby znajdowały się one bezpośrednio w tabeli. Pisząc prawie mam na myśli to, że możemy je czytać ale nie możemy do nich pisać.
Aby móc korzystać ten sposób z pliku tekstowego, Oracle musi mieć zmapowany katalog w którym owy plik się znajduje. Zaloguj się jako SYS i wykonaj poniższe polecenia:
create directory loader as 'c:\andrzej\loader'
grant read, write on directory loader to hr
Oczywiście wpisz adres katalogu na swoim dysku. Katalog musi fizycznie istnieć na dysku, a użytkownik systemowy Oracle (z którego baza korzysta w systemie) musi mieć do niego dostęp. Jeśli pracujesz w Linuksie, nadaj odpowiedni chmod. Druga linia powyższego kodu nadaje uprawnienia do zapisu i odczytu ale użytkownikowi bazodanowemu a nie systemowemu.
Zaloguj się jako user któremu nadałeś uprawnienia do tego katalogu (tutaj HR) , a następnie uruchom poniższy kod.
CREATE TABLE regiony_plik (
region_id number,
region_name varchar2(100)
)
ORGANIZATION EXTERNAL (
TYPE oracle_loader
DEFAULT DIRECTORY loader
ACCESS PARAMETERS(
FIELDS TERMINATED BY ','
MISSING FIELD VALUES ARE NULL
(region_id, region_name)
)
LOCATION ('regiony.csv')
)
REJECT LIMIT UNLIMITED;
Zauważ że jest to zwyczajna definicja tabeli z pewnymi dodatkami.
Type oracle_loader oznacza że jest to tabela z której będziemy korzystać w sposób opisany na początku tego posta.
Default directory loader - tutaj podajemy nazwę katalogu pod jaką funkcjonuje on w Oracle - nie podajemy tutaj żadnej ścieżki. Po to tworzyliśmy wcześniej mapowanie katalogu.
Fields terminated by ',' określa znacznik jaki rozdziela poszczególne kolumny w pliku csv.
Missing field values are null mówi oraclowi że puste wartości pomiędzy znakami rozdzielającymi to nie błąd tylko po prostu pusta wartość w kolumnie.
(region_id, region_name) to nazwy kolumn do jakich mają w podanej kolejności być ładowane dane.
Location('regiony.csv') określa nazwę pliku w zmapowanym katalogu.
Zrób sobie jakiegoś selecta na stworzonej tabeli by upewnić się że wszystko gra. Niektóre błędy mogą pojawić się dopiero teraz.

I voila!
W Oracle jest opcja stworzenia specjalnej tabeli będącej niejako nakładką na plik tekstowy. Sprawia ona że możemy korzystać z danych w pliku tekstowym prawie w taki sam sposób jakby znajdowały się one bezpośrednio w tabeli. Pisząc prawie mam na myśli to, że możemy je czytać ale nie możemy do nich pisać.
Aby móc korzystać ten sposób z pliku tekstowego, Oracle musi mieć zmapowany katalog w którym owy plik się znajduje. Zaloguj się jako SYS i wykonaj poniższe polecenia:
create directory loader as 'c:\andrzej\loader'
grant read, write on directory loader to hr
Oczywiście wpisz adres katalogu na swoim dysku. Katalog musi fizycznie istnieć na dysku, a użytkownik systemowy Oracle (z którego baza korzysta w systemie) musi mieć do niego dostęp. Jeśli pracujesz w Linuksie, nadaj odpowiedni chmod. Druga linia powyższego kodu nadaje uprawnienia do zapisu i odczytu ale użytkownikowi bazodanowemu a nie systemowemu.
Zaloguj się jako user któremu nadałeś uprawnienia do tego katalogu (tutaj HR) , a następnie uruchom poniższy kod.
CREATE TABLE regiony_plik (
region_id number,
region_name varchar2(100)
)
ORGANIZATION EXTERNAL (
TYPE oracle_loader
DEFAULT DIRECTORY loader
ACCESS PARAMETERS(
FIELDS TERMINATED BY ','
MISSING FIELD VALUES ARE NULL
(region_id, region_name)
)
LOCATION ('regiony.csv')
)
REJECT LIMIT UNLIMITED;
Zauważ że jest to zwyczajna definicja tabeli z pewnymi dodatkami.
Type oracle_loader oznacza że jest to tabela z której będziemy korzystać w sposób opisany na początku tego posta.
Default directory loader - tutaj podajemy nazwę katalogu pod jaką funkcjonuje on w Oracle - nie podajemy tutaj żadnej ścieżki. Po to tworzyliśmy wcześniej mapowanie katalogu.
Fields terminated by ',' określa znacznik jaki rozdziela poszczególne kolumny w pliku csv.
Missing field values are null mówi oraclowi że puste wartości pomiędzy znakami rozdzielającymi to nie błąd tylko po prostu pusta wartość w kolumnie.
(region_id, region_name) to nazwy kolumn do jakich mają w podanej kolejności być ładowane dane.
Location('regiony.csv') określa nazwę pliku w zmapowanym katalogu.
Zrób sobie jakiegoś selecta na stworzonej tabeli by upewnić się że wszystko gra. Niektóre błędy mogą pojawić się dopiero teraz.

I voila!
SQL Loader - czyli wciągamy do Oracle dane z plików CSV
Jeśli przenosimy dane pomiędzy dwoma rodzajami baz (z czego docelowa to Oracle :) ), albo ewentualnie chcemy wczytać coś z Excela najlepiej wyeksportować ze źródła dane do postaci pliku CSV, a następnie wciągać SQL Loaderem.
Na potrzeby tej lekcji wyeksportuj zawartość tabeli regions z schematu hr do pliku CSV. Możesz to zrobić klikając w SQL Developerze prawym przyciskiem myszy na nazwę tabeli a następnie klikając export data--> csv.
Stwórz sobie teraz tabelkę do której będziemy wciągać dane. Moglibyśmy wciągnąć dane do istniejącej już tabeli, ale sql loader nadpisze wiersze jeśli trafi na identyczne. Na potrzeby ćwiczeń stwórz tabelkę która będzie kopią (samej struktury) tabeli regions:
 Kod:
Kod:
create table regions2 as select * from regions where 1=2
Ten warunek WHERE 1=2 jest po to by przy kopiowaniu tabeli nie kopiował jej zawartości.
Jak już będziesz miał tabelę to stwórz sobie plik kontrolny który będzie sterował poczynaniami sqlloadera, z analogiczną zawartością:
load data
infile 'c:\andrzej\ld\regions.csv'
append into table regions2
fields terminated by ','
(region_id,region_name)
load data zostawiasz w spokoju.
infile określa plik csv z którego wciągane będą dane.
Append into table regions2 to znaczy że dane będą wciągane do tabeli regions2
fields terminated by ',' oznacza znak który rozdziela kolumny - oczywiście może być co inny znak np. bardzo często jest to średnik ; .
Ostatnia linijka oznacza nazwy kolumn do których w wybranej tabeli mają zostać wciągane dane we wskazanej kolejności.
Zapisz plik i w konsoli wpisz coś takiego:
sqlldr hr/hr control=c:\andrzej\ld\ustawienia.txt
hr/hr to nazwa użyszkodnika z poziomu którego robimy wciąganie danych (musi mieć do danej tabeli uprawnienia oczywiście) . Control wskazuje na położenie pliku kontrolnego który sobie przed momentem stworzyłeś.

Zajrzyj teraz do tabeli regions2. Masz tam dane z pliku csv :)
Na potrzeby tej lekcji wyeksportuj zawartość tabeli regions z schematu hr do pliku CSV. Możesz to zrobić klikając w SQL Developerze prawym przyciskiem myszy na nazwę tabeli a następnie klikając export data--> csv.
Stwórz sobie teraz tabelkę do której będziemy wciągać dane. Moglibyśmy wciągnąć dane do istniejącej już tabeli, ale sql loader nadpisze wiersze jeśli trafi na identyczne. Na potrzeby ćwiczeń stwórz tabelkę która będzie kopią (samej struktury) tabeli regions:

create table regions2 as select * from regions where 1=2
Ten warunek WHERE 1=2 jest po to by przy kopiowaniu tabeli nie kopiował jej zawartości.
Jak już będziesz miał tabelę to stwórz sobie plik kontrolny który będzie sterował poczynaniami sqlloadera, z analogiczną zawartością:
load data
infile 'c:\andrzej\ld\regions.csv'
append into table regions2
fields terminated by ','
(region_id,region_name)
load data zostawiasz w spokoju.
infile określa plik csv z którego wciągane będą dane.
Append into table regions2 to znaczy że dane będą wciągane do tabeli regions2
fields terminated by ',' oznacza znak który rozdziela kolumny - oczywiście może być co inny znak np. bardzo często jest to średnik ; .
Ostatnia linijka oznacza nazwy kolumn do których w wybranej tabeli mają zostać wciągane dane we wskazanej kolejności.
Zapisz plik i w konsoli wpisz coś takiego:
sqlldr hr/hr control=c:\andrzej\ld\ustawienia.txt
hr/hr to nazwa użyszkodnika z poziomu którego robimy wciąganie danych (musi mieć do danej tabeli uprawnienia oczywiście) . Control wskazuje na położenie pliku kontrolnego który sobie przed momentem stworzyłeś.

Zajrzyj teraz do tabeli regions2. Masz tam dane z pliku csv :)
Export i import danych dla NIE-adminów
Dzisiaj przedstawiam proste techniki importu i eksportu danych z bazy Oracle dla normalnych developerów Oracle (tj. nie geeków siedzących 25 godzin na dobę przed komputerem znających każde najdrobniejsze pojęcie związane z Oracle, wszystkie możliwe struktury i dostępne parametry dla wszystkich programów, tylko dla takich co pracują jak biali ludzie, mają trochę życia, może nawet psa..).
W Oracle mamy dwa fajne programy do tego celu.
Generalnie przy użyciu programów exp i imp możemy eksportować i importować :
-całą bazę
-wybrany schemat
-wybrane tabele
Eksport danych
Najprostszy jest eksport całej bazy, swoją drogą może się przydać gdybyśmy coś napsuli :P

Kod:
exp userid=system/assembler1 file='c:\andrzej\ei\calosc.dat' log='c:\andrzej\ei\.calosc.log' FULL=Y
To co następuje po userid to nazwa użytkownika łamana przez hasło. W tym wypadku muszę to zrobić jako system, ponieważ jako zwykły użytkownik nie mam dostępu do całej bazy (a całą chcę eksportować).
Po file podaję nazwę pliku do którego zostanie wrzucona zawartość bazy. Plik stworzy się sam, ale struktura katalogów już musi być. Po log podaję plik do którego mają być zrzucane logi. Podawanie tego nie jest obowiązkowe. Opcja Full=y nakazuje eksport całej bazy. Jeśli jej nie podasz, musisz wyeksportować schemat, albo tabelę, ale i tak musisz określić które.
Eksport całego schematu:

Kod:
exp userid=hr/hr file='c:\andrzej\ei\schemat.dat' log='c:\andrzej\ei\schemat.log' owner=hr
Parametry userid, file, log znaczą to samo co poprzednio :). Eksportuję jako user hr swój własny schemat. Oczywiście mogę eksportować również schematy innych userów, ale muszę do tego być zalogowany jako user system (albo user który jest ownerem schematu).
Poza tym zamiast "full=y" pojawiło się "owner=hr", co oznacza że wyeksportowany ma zostać cały schemat usera hr.
Na wypadek gdyby nie chciało Ci się wstać z fotela i zrobić eksport na kompie stojącym 2 metry dalej (albo serwerze pilnie strzeżonego przez 1435454 drzwi, strażników i bramek) to możesz zrobić to zdalnie, dodając w userid "@adres_ip" :

Eksport wybranych tabel
Możesz chcieć też zrobić sobie kopię zapasową tylko kilku tabel. Do tego celu w miejsce wcześniejszego full=y czy owner=hr wpisujesz np. tables=employees, departments :

Jak już wyrzuciliśmy dane z bazy, to może zechcemy sobie je zaimportować z powrotem albo wrzucić na innych serwerze. Do takich zabaw używamy programu imp.
Import całej bazy

Kod:
imp userid=system/assember1 file='c:\andrzej\ei\calosc.dat' log='c:\andrzej\ei\iportall.log' full=y destroy=y
Parametr userid - wiadomo to samo co przy exp, wiadomo że jak całość wciągamy to logujemy się jako user system. File to plik z wcześniejszego eksportu danych, log tak jak wcześniej, full=y bo wciągamy całość, destroy=y oznacza, że jeśli istnieje już obiekt w bazie o takiej nazwie to zostanie skasowany i nadpisany. Jeśli tego nie dodamy, to w takiej sytuacji zacznie krzyczeć (chyba że dodamy ignore=y, wtedy olewa problemy).
Chciałbym już pisać dalej i robić screeny ale jeszcze mi się importuje....
Import schematu
Importować możemy zawartość schematu nie tylko z powrotem do schematu usera z którego zostały dane wyciągnięte, ale też dane możemy wstawić innemu userowi. Dlatego przy imporcie nie ma już 'owner=hr', ale za to jest 'touser=hr' określający do schematu jakiego usera mają dane zostać wrzucone, oraz 'fromuser=hr'
czyli schemat jakiego usera może być wciągnięty ( bo jeżeli importujemy jakiś schemat z eksportu całej bazy, to przecież mamy tam schematów od pytki i trzeba któryś wybrać ).

Tutaj też mógłbym dać np. log='costamcostam' jak przy eksporcie, ale mi się nie chciało pisać (czytaj: da się).
Import poszczególnych tabel
Podobnie jak przy imporcie schematu robię fromuser i touser - w tym względzie działa to tak samo. Wybieram sobie też tabele które chcę zaimportować.

Kod:
imp userid=hr/hr file='c:\andrzej\tabele.dat' fromuser=hr touser=hr tables=employees
Uważaj tylko z tym importem, bo Oracle nadpisuje tabele importowane bez żadnej gadki.
W nagrodę że chciało Ci się tyle czytać masz zagadkę: Co to jest : "nie świeci i nie mieści się w dupie?"
..
...
....
..
..
"radziecka maszyna do świecenia w dupie".
Programy exp i imp mają jeszcze kilka mniej lub bardziej przydatnych parametrów. Wszystkie znajdziesz tutaj :)
W Oracle mamy dwa fajne programy do tego celu.
Generalnie przy użyciu programów exp i imp możemy eksportować i importować :
-całą bazę
-wybrany schemat
-wybrane tabele
Eksport danych
Najprostszy jest eksport całej bazy, swoją drogą może się przydać gdybyśmy coś napsuli :P

Kod:
exp userid=system/assembler1 file='c:\andrzej\ei\calosc.dat' log='c:\andrzej\ei\.calosc.log' FULL=Y
To co następuje po userid to nazwa użytkownika łamana przez hasło. W tym wypadku muszę to zrobić jako system, ponieważ jako zwykły użytkownik nie mam dostępu do całej bazy (a całą chcę eksportować).
Po file podaję nazwę pliku do którego zostanie wrzucona zawartość bazy. Plik stworzy się sam, ale struktura katalogów już musi być. Po log podaję plik do którego mają być zrzucane logi. Podawanie tego nie jest obowiązkowe. Opcja Full=y nakazuje eksport całej bazy. Jeśli jej nie podasz, musisz wyeksportować schemat, albo tabelę, ale i tak musisz określić które.
Eksport całego schematu:

Kod:
exp userid=hr/hr file='c:\andrzej\ei\schemat.dat' log='c:\andrzej\ei\schemat.log' owner=hr
Parametry userid, file, log znaczą to samo co poprzednio :). Eksportuję jako user hr swój własny schemat. Oczywiście mogę eksportować również schematy innych userów, ale muszę do tego być zalogowany jako user system (albo user który jest ownerem schematu).
Poza tym zamiast "full=y" pojawiło się "owner=hr", co oznacza że wyeksportowany ma zostać cały schemat usera hr.
Na wypadek gdyby nie chciało Ci się wstać z fotela i zrobić eksport na kompie stojącym 2 metry dalej (albo serwerze pilnie strzeżonego przez 1435454 drzwi, strażników i bramek) to możesz zrobić to zdalnie, dodając w userid "@adres_ip" :

Eksport wybranych tabel
Możesz chcieć też zrobić sobie kopię zapasową tylko kilku tabel. Do tego celu w miejsce wcześniejszego full=y czy owner=hr wpisujesz np. tables=employees, departments :

Import danych
Jak już wyrzuciliśmy dane z bazy, to może zechcemy sobie je zaimportować z powrotem albo wrzucić na innych serwerze. Do takich zabaw używamy programu imp.
Import całej bazy
Kod:
imp userid=system/assember1 file='c:\andrzej\ei\calosc.dat' log='c:\andrzej\ei\iportall.log' full=y destroy=y
Parametr userid - wiadomo to samo co przy exp, wiadomo że jak całość wciągamy to logujemy się jako user system. File to plik z wcześniejszego eksportu danych, log tak jak wcześniej, full=y bo wciągamy całość, destroy=y oznacza, że jeśli istnieje już obiekt w bazie o takiej nazwie to zostanie skasowany i nadpisany. Jeśli tego nie dodamy, to w takiej sytuacji zacznie krzyczeć (chyba że dodamy ignore=y, wtedy olewa problemy).
Chciałbym już pisać dalej i robić screeny ale jeszcze mi się importuje....
Import schematu
Importować możemy zawartość schematu nie tylko z powrotem do schematu usera z którego zostały dane wyciągnięte, ale też dane możemy wstawić innemu userowi. Dlatego przy imporcie nie ma już 'owner=hr', ale za to jest 'touser=hr' określający do schematu jakiego usera mają dane zostać wrzucone, oraz 'fromuser=hr'
czyli schemat jakiego usera może być wciągnięty ( bo jeżeli importujemy jakiś schemat z eksportu całej bazy, to przecież mamy tam schematów od pytki i trzeba któryś wybrać ).

Kod:
imp userid=hr/hr file='c:\andrzej\ei\schemat.dat' fromuser=hr touser=hr destroy=y
Tutaj też mógłbym dać np. log='costamcostam' jak przy eksporcie, ale mi się nie chciało pisać (czytaj: da się).
Import poszczególnych tabel
Podobnie jak przy imporcie schematu robię fromuser i touser - w tym względzie działa to tak samo. Wybieram sobie też tabele które chcę zaimportować.

Kod:
imp userid=hr/hr file='c:\andrzej\tabele.dat' fromuser=hr touser=hr tables=employees
Uważaj tylko z tym importem, bo Oracle nadpisuje tabele importowane bez żadnej gadki.
W nagrodę że chciało Ci się tyle czytać masz zagadkę: Co to jest : "nie świeci i nie mieści się w dupie?"
..
...
....
..
..
"radziecka maszyna do świecenia w dupie".
Programy exp i imp mają jeszcze kilka mniej lub bardziej przydatnych parametrów. Wszystkie znajdziesz tutaj :)
środa, 24 listopada 2010
Partycjonowanie tabel
Dobre wieści:
Jeśli mamy duuuuuże tabele (tzn. zawierające dużo danych) to ich przetwarzanie możemy sobie usprawnić dzieląc je na takie wirtualne części nazywane partycjami. Dzięki temu:
Partycje możemy generalnie tworzyć na podstawie zawartości lub podzielić na sekcje równej wielkości. Dzielone na podstawie zawartości mogą być różnych rozmiarów - możemy mieć przykładowo milion faktur z tego roku, ale 5 milionów z zeszłego.
Partycjonowanie względem zawartości:

Powyżej podzieliłem tablicę na partycję względem zawartości kolumny salary na sekcje.
Partycjonowanie hashowe (takie na równej wielkości kawałki):

Złe wieści:
Jeśli mamy duuuuuże tabele (tzn. zawierające dużo danych) to ich przetwarzanie możemy sobie usprawnić dzieląc je na takie wirtualne części nazywane partycjami. Dzięki temu:
- Można zadać zapytanie tylko do jednej partycji w tabeli i dzięki temu nie ma potrzeby przetwarzania całej tabeli (co jak się nie trudno domyślić jest szybsze)
- Joiny śmigają szybciej na takiej jednej partycji niż na całej tabeli, to samo grupowania, sortowanie i cała reszta możliwych sposobów na męczenie bazy.
- Partycje możemy sobie stworzyć na podstawie zawartości kolumny w tabeli, dzięki czemu możemy np. mieć szybszy dostęp do faktur przykładowo z tego roku.
- W ogóle idą za tym wszystkie korzyści związane z mniejszą ilością danych do przetworzenia.
Partycje możemy generalnie tworzyć na podstawie zawartości lub podzielić na sekcje równej wielkości. Dzielone na podstawie zawartości mogą być różnych rozmiarów - możemy mieć przykładowo milion faktur z tego roku, ale 5 milionów z zeszłego.
Partycjonowanie względem zawartości:

Powyżej podzieliłem tablicę na partycję względem zawartości kolumny salary na sekcje.
Partycjonowanie hashowe (takie na równej wielkości kawałki):

Złe wieści:
- Taka opcja dostępna jest tylko w wersji Enterprise (która kosztuje tyle co dom Twój i wszystkich Twoich sąsiadów z całej wioski :P )
- Sama tylko opcja kosztuje tyle co całkiem niezgorszy samochód
Tabele tymczasowe
W Oracle możemy stworzyć tabelę tymczasową która będzie przechowywać dane tylko w czasie bieżącego połączenia.
Tabela tymczasowa dostępna jest z wielu sesji.
Zawartość takiej tabeli widoczna jest tylko dla aktualnej sesji.
Wykorzystujemy taki byt do chwilowego przechowywania danych.
Możemy stworzyć taką tabelę w sposób zbliżony do tworzenia zwykłej tabeli (różnica w dodaniu GLOBAL TEMPORARY):
Podając kolumny:

Na podstawie zapytania :

Warunek "where 1!=1" jest po to, by skopiować tylko strukturę tabeli bez danych. Posiadając taką tabelę, mamy możliwość zrobienia sobie czegoś w rodzaju backupu. Czyli wrzucamy sobie przykładowo zawartość tabeli employees do tabeli tymczasowej, robimy jakieś fiku miku na tabeli employees a w razie jakbyśmy coś spraprali mamy poprzedni stan danych łatwo dostępny w tabeli tymczasowej bez potrzeby robienia normalnych backupów.

Wyższość tego rozwiązania nad tworzeniem zwykłej tabeli do tego samego celu, polega na tym że po zakończeniu sesji dane z tabeli tymczasowej znikają. Dzięki temu nie zostają nam śmieci zajmujące miejsce, a zupełnie nie potrzebne nam później.
Tabela tymczasowa dostępna jest z wielu sesji.
Zawartość takiej tabeli widoczna jest tylko dla aktualnej sesji.
Wykorzystujemy taki byt do chwilowego przechowywania danych.
Możemy stworzyć taką tabelę w sposób zbliżony do tworzenia zwykłej tabeli (różnica w dodaniu GLOBAL TEMPORARY):
Podając kolumny:

Na podstawie zapytania :

Warunek "where 1!=1" jest po to, by skopiować tylko strukturę tabeli bez danych. Posiadając taką tabelę, mamy możliwość zrobienia sobie czegoś w rodzaju backupu. Czyli wrzucamy sobie przykładowo zawartość tabeli employees do tabeli tymczasowej, robimy jakieś fiku miku na tabeli employees a w razie jakbyśmy coś spraprali mamy poprzedni stan danych łatwo dostępny w tabeli tymczasowej bez potrzeby robienia normalnych backupów.

Wyższość tego rozwiązania nad tworzeniem zwykłej tabeli do tego samego celu, polega na tym że po zakończeniu sesji dane z tabeli tymczasowej znikają. Dzięki temu nie zostają nam śmieci zajmujące miejsce, a zupełnie nie potrzebne nam później.
sobota, 20 listopada 2010
Kurs Oracle PL/SQL. Wyzwalacze typu INSTEAD-OF
Na niektórych widokach nie można wykonywać operacji DML (kasowania, zmiany, dodawania wierszy) . Przykładem może być widok oparty o połączone tabele:
Ponieważ w tym widoku znajdują się dane pochodzące z dwóch tabel, nie mogę na nim wykonać operacji delete i muszę zastosować wyzwalacz typu instead-of.
Dane pochodzące z widoku:

Widzimy że w jednej lokalizacji może znajdować się więcej niż jeden departament. Teraz chciałbym, aby przy usuwaniu danego departamentu :
- jeśli wybrany departament jest jedynym w lokalizacji, automatycznie powinna zostać skasowana również lokalizacja
- jeśli w lokalizacji w której znajduje się wybrany departament znajdują się inne departamenty, to lokalizacja powinna zostać nienaruszona, natomiast powinien zostać usunięty departament.

Ćwiczenia
1.Stwórz tabelę logs zawierającą pola info typu varchar2(100), time typu date. Stwórz wyzwalacz który przy każdej operacji zmieniającej w jakikolwiek sposób dane w tabeli jobs, do tabeli logs została wprowadzona informacja o typie zmiany oraz czasie kiedy ta zmiana została wykonana.
2. Zablokuj przy pomocy wyzwalacza możliwość zmiany istniejących danych w tabeli employees w taki sposób by zmniejszona została wartość w kolumnie salary dla któregokolwiek wiersza.
3.Do tabeli employees dodaj kolumnę typu liczbowego o nazwie month_salary. Spraw by przy każdym insercie do tej tabeli uwzględniającym informacje o wypłacie (kolumna "salary"), do nowo stworzonej kolumny była wprowadzana 1/12 wartości salary. Jeśli żadne dane nie zostaną wprowadzone do kolumny salary, przechwyć obsługę błędu i wyświetl na konsoli informacje o brakujących danych.
Ten temat omawiam na poniższych szkoleniach:
• Programowanie w PL/SQL
• Podstawy SQL i PL/SQL
Możesz w nich uczestniczyć, a jako czytelnik tego bloga otrzymasz 10% zniżki - poinformuj o tym fakcie konsultanta.
Kurs Oracle PL/SQL. Predykaty w wyzwalaczach
Jeden wyzwalacz może reagować na więcej niż jedno zdarzenie na obiekcie. Wystarczy dodać kolejne warunki w definicji wyzwalacza. W poniższym przykładzie widoczny jest wyzwalacz który zareaguje na insert, update oraz delete.
Wygodnie jest mieć jeden wyzwalacz przypisany do tabeli, jednak muszę w takim wypadku mieć możliwość rozróżnienia jakie polecenie zostało wykonane na tabeli. Rozróżniam je dzięki predykatom INSERTING,DELETING,UPDATING. Predykaty mogę stosować w warunkach takich jak IF, a dzięki temu wykonywać różne operacje w zależności od tego jaka instrukcja została wykonana.

Ten temat omawiam na poniższych szkoleniach:
• Programowanie w PL/SQL
• Podstawy SQL i PL/SQL
Możesz w nich uczestniczyć, a jako czytelnik tego bloga otrzymasz 10% zniżki - poinformuj o tym fakcie konsultanta.
Kurs Oracle PL/SQL. Wyzwalacze wierszowe
Istnieje możliwość modyfikowania danych przez wyzwalacz, zanim te zostaną wstawione do tabeli, lub zanim wiersz w tabeli zostanie zmieniony tymi danymi.
Możemy wykonać takie działania, ponieważ istnieją dwie zmienne :new oraz :old zawierające cały modyfikowany, dodawany lub usuwany wiersz. Korzystając z tych zmiennych możemy przed wstawieniem danych do tabeli pobrać je, zmodyfikować, a następnie wstawić już zmienione dane.
Aby móc korzystać ze zmiennych :new i :old muszę dodać dodatkową klauzulę „FOR EACH ROW” do definicji wyzwalacza.
Na poniższym przykładzie prezentuję przykład modyfikacji danych wstawianych do tabeli. Musimy pamiętać, by takie operacje jak modyfikacje wstawianych danych wykonywać w wyzwalaczu uruchamianym PRZED zdarzeniem, a nie po.

Nakładając wyzwalacz na UPDATE tabeli mam również dostęp do zmiennej :old. Zawiera ona zmieniany wiersz w postaci w jakiej występował przed modyfikacją. Mogę więc określić jak zmieniana nazwa stanowiska brzmiała przed, a jak po zmianie wiersza:

Mam też możliwość zdefiniowania wyzwalacza który będzie się wykonywał tylko jeśli spełniony zostanie warunek dotyczący wprowadzanych danych.
Uwaga: W ciele wyzwalaczy nie może być instrukcji które modyfikują strukturę lub zawartość tabeli na którą nałożony jest wyzwalacz. Nie mogą też zawierać instrukcji wpływających na transakcję ani odwoływać się do podprogramów zawierających takie instrukcje.
W wyzwalaczu CUSTOM3 wyświetlona zostanie informacja tylko jeśli wartość MAX_SALARY wstawianego wiersza będzie wyższa niż 10000. Zwróć uwagę, że wykonywane są również inne wyzwalacze które wcześniej nałożyłem na działania na tej tabeli.

Ten temat omawiam na poniższych szkoleniach:
• Programowanie w PL/SQL
• Podstawy SQL i PL/SQL
Możesz w nich uczestniczyć, a jako czytelnik tego bloga otrzymasz 10% zniżki - poinformuj o tym fakcie konsultanta.
Kurs Oracle PL/SQL. Wyzwalacze obiektowe
Wyzwalacze są podprogramami wywoływanymi jako reakcja na pewne zdarzenie na obiekcie bazy danych. Przykładowo tworząc wyzwalacz możemy określić jakie działanie ma podjąć w przypadku gdyby użytkownik wprowadził dane do wybranej tabeli.
Triggery są znakomitym narzędziem do logowania zdarzeń w systemie. Możemy stworzyć własną tabelę z logami, następnie wyzwalacze które będą do tej tabeli wstawiać kolejne wiersze w zależności od działań na obiektach bazy danych.
Tworzenie wyzwalaczy
Ogólna konstrukcja tworzenia wyzwalaczy wygląda w taki sposób:
CREATE OR REPLACE TRIGGER nazwa_triggera
BEFORE/AFTER
DELETE/UPDATE/INSERT/INSERT OR UPDATE OR DELETE
ON nazwa_tabeli
instrukcje które mają zostać wykonane.
W poniższym przykładzie utworzyłem wyzwalacz który przed wprowadzeniem wiersza do tabeli JOBS ma wyświetlić na konsoli wiadomość „ktoś wstawił wiersz do tabeli jobs!!”
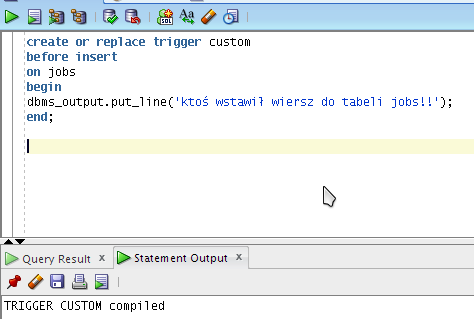
Od tego momentu, za każdym razem gdy będzie wstawiany wiersz do tabeli jobs zostanie wywołany wyzwalacz CUSTOM. Działania w nim opisane będą wykonywane PRZED wprowadzeniem danych do tej tabeli, ponieważ użyłem klauzuli BEFORE.
Poniższa ilustracja prezentuje efekt działania wyzwalacza. Wprowadziłem wiersz do tabeli jobs, a Oracle wywołał mój wcześniej stworzony wyzwalacz który wypisał na konsoli wiadomość.

Ten temat omawiam na poniższych szkoleniach:
• Programowanie w PL/SQL
• Podstawy SQL i PL/SQL
Możesz w nich uczestniczyć, a jako czytelnik tego bloga otrzymasz 10% zniżki - poinformuj o tym fakcie konsultanta.
Kurs Oracle SQL. Pakiety - sekcja inicjalizacyjna pakietu
W niektórych sytuacjach zmienne w pakiecie muszą zostać zainicjalizowane dynamicznie np. wartością pochodzącą z zapytania.
Do naszego ćwiczebnego pakietu dodaję zmienną dostępną dla wszystkich podprogramów w tym pakiecie:

Chciałbym teraz aby do nowej zmiennej podczas inicjalizacji pakietu (czyli wtedy gdy po raz pierwszy w danej sesji odwołuję się do jakiegoś składnika pakietu) została przypisana dynamiczna wartość – w tym wypadku pochodząca z jednej z funkcji tegoż pakietu.
W tym celu muszę uzupełnić sekcję inicjującą pakietu. Wykonuję to poprzez dodanie poleceń które mają zostać wykonane przed końcem treści pakietu, poprzedzając je słowem „BEGIN”.:

Do zmiennej „zmienna” zostanie przypisana wartość będąca wynikiem działania funkcji „srednia_zarobkow_dzialu”. Zwróć uwagę że jeśli zmieni się wartość jaka wynikałaby z tej funkcji w trakcie korzystania z pakietu, ale już po inicjalizacji – zawartość zmiennej zainicjalizowanej w ten sposób nie zmieni się.
Ćwiczenia
1. Stwórz pakiet który będzie "sercem" prostego programu kadrowo - płacowego. Pakiet nazwij hrmanager.
2. Do pakietu hrmanager dodaj funkcję która zwróci największe zarobki w całej firmie.
3. Do pakietu hrmanager dodaj procedurę o nazwie "srednia" która pobiera jako parametr id działu. Procedura powinna wyświetlić na konsoli średnią zarobków w dziale o id takim jak przyjęty parametr.
4. Do pakietu hrmanager dodaj procedurę o nazwie "srednia" która pobiera jako parametry id działu oraz id managera. Procedura powinna wyświetlić na konsoli średnią zarobków w dziale o id takim jak przyjęty pierwszy parametr, ale tylko tych osób które są podwładnymi managera o numerze podanym jako parametr drugi.
5. Do pakietu hrmanager dodaj procedurę o nazwie "srednia" która pobiera jako parametry nazwę działu oraz nazwisko managera. Procedura powinna wyświetlić na konsoli średnią zarobków w dziale o nazwie takiej jak przyjęty pierwszy parametr, ale tylko tych osób które są podwładnymi managera o nazwisku podanym jako parametr drugi. Procedura powinna wyświetlać na konsoli informację, jeśli w wyniku zapytania zostanie zwrócone 0 wierszy.
Ten temat omawiam na poniższych szkoleniach:
• Programowanie w PL/SQL
• Podstawy SQL i PL/SQL
Możesz w nich uczestniczyć, a jako czytelnik tego bloga otrzymasz 10% zniżki - poinformuj o tym fakcie konsultanta.
Kurs Oracle PL/SQL.Pakiety - przeciążanie procedur i funkcji
W jednym pakiecie możemy zdefiniować kilka procedur lub funkcji o identycznych nazwach, jednak muszą one różnić się ilością lub typem parametrów przyjmowanych. Nie można zdefiniować identycznych podprogramów jeśli różnią się jedynie zwracanym typem lub typami parametrów IN, IN OUT i OUT.



Ten temat omawiam na poniższych szkoleniach:
• Programowanie w PL/SQL
• Podstawy SQL i PL/SQL
Możesz w nich uczestniczyć, a jako czytelnik tego bloga otrzymasz 10% zniżki - poinformuj o tym fakcie konsultanta.
W poniższym przykładzie dodałem drugą funkcję „srednia_zarobkow_dzialu” różniącą się tylko jednym parametrem. Dodałem parametr id_managera aby wyświetlać średnie zarobków w danym dziale, obliczane na podstawie zarobków pracowników podległych konkretnemu managerowi w tym dziale.

Następnym krokiem było rozbudowanie części implementacji pakietu o ciało nowej funkcji:

Mogę teraz wykorzystać obie wersje funkcji, a to która z nich zostanie użyta zależeć będzie od ilości podanych parametrów:

Ten temat omawiam na poniższych szkoleniach:
• Programowanie w PL/SQL
• Podstawy SQL i PL/SQL
Możesz w nich uczestniczyć, a jako czytelnik tego bloga otrzymasz 10% zniżki - poinformuj o tym fakcie konsultanta.
Subskrybuj:
Posty (Atom)