Tabele
Tworzenie
tabeli
Tworząc
tabelę podajemy pola jakie ta tabela ma posiadać, rodzaj danych
przechowywanych przez te pola oraz własności tabeli:

Podczas
tworzenia możemy nakładać wszystkie constrainty takie jak
primary key czy foreign key. Możemy również ustawić
dodawanie wartości domyślnej w przypadku nie wprowadzenia wartości
żadnej dla danego pola podczas uzupełniania tabeli. Odbywa się to
przy pomocy klauzuli DEFAULT.
Tworzenie
tabeli na podstawie zapytania
Tabelę
możemy stworzyć również na podstawie zapytania. Stworzona w ten
sposób tabela będzie zawierała wszystkie dane które zostaną nam
zwrócone jako wynik zapytania. Jeśli chcemy aby została stworzona
tylko struktura, możemy po klauzuli WHERE dodać jakiś
warunek który nigdy nie może zajść.

Usuwanie
tabeli
Aby
usunąć tabelę korzystamy z polecenia drop:

Zmiana
nazwy tabeli
Aby
zmienić nazwę tabeli stosujemy polecenie RENAME:

Dodawanie
kolumn
Do
dodawania kolumn do tabeli wykorzystujemy ALTER TABLE. Możemy
wykorzystywać wszystkie parametry jakie stosujemy podczas tworzenia
tabeli (parametry dla kolumny).

Usuwanie
kolumn
Do
usuwania kolumn wykorzystujemy DROP COLUMN:

Zmiana
własności kolumn
Aby
zmienić typ kolumny stosujemy polecenie MODIFY. Typ kolumny
zmienić możemy, o ile dane zawarte w tej kolumnie mogą zostać
przekonwertowane do nowego typu. Np. możemy zmienić długość
kolumny, możemy zmienić typ liczbowy w typ tekstowy, ale nie możemy
zmienić typu tekstowego w liczbowy jeśli dane zawarte w kolumnie
liczbowej nie są wartościami numerycznymi.

Więzy
integralności
Dzięki
więzom integralności nie można tak zmodyfikować danych by
straciły on spójność. Są zbiorem zasad nałożonych na tabele w
bazie danych.
Primary
Key
Zapewnia
unikalność wartości w kolumnie. Najczęściej zakładany jest na
kolumnę która przechowuje dane jednoznacznie określające
pojedynczy wiersz. W tabeli może być tylko jeden klucz główny.
Zapewnia nie występowanie wartości NULL
w kolumnie na którą jest nałożony.
Unique
Zapewnia
unikalność wartości w kolumnie, jednak w przeciwieństwie do
PRIMARY KEY takich kluczy
może być więcej niż jeden, oraz umożliwia występowanie wartości
NULL.
NOT
NULL
Zapobiega
wstawianiu wartości NULL do
kolumny.
Check
Zapewnia
że wartość wstawiana do kolumny spełnia wymagany warunek
logiczny. Nie można w nim wykorzystywać odwołań do innych tabel,
funkcji agregujących, SYSDATE.
Foreign
key
Jest
to klucz obcy. Służy do definiowania relacji pomiędzy tabelami.
Zapewnia że rekord w tabeli podrzędnej zawsze będzie miał swojego
odpowiednika w tabeli nadrzędnej. Klucz obcy musi się odwoływać
do kolumny (kolumn) w tabeli nadrzędnej, na których założony jest
UNIQUE lub klucz główny.
Zakładanie
konstraintów
Więzy
możemy zakładać na dwa sposoby. Przy tworzeniu tabeli, oraz
nakładając je na już istniejącą
tabelę.
Poniżej przykład zakładania więzów już przy tworzeniu tabeli:

Przykład
zakładania konstraintów na istniejącej tabeli:

Wyjątek
od reguły stanowi NOT NULL. Własność NULL/NOT NULL ustawiamy
poprzez zmianę stanu:

Włączanie
i wyłączanie konstraintów
Constrainty
możemy włączyć lub wyłączyć. Możliwość ta staje się
przydatna gdy chcemy wykonać czynność którą uniemożliwiłby nam
założony constraint. Przykładowo zdejmujemy klucz obcy (FOREIGN
KEY) z tabeli jeśli uzupełniamy ją danymi które nie mają swoich
odpowiedników w tabeli nadrzędnej.

Możemy
po wykonaniu zaplanowanych czynności włączyć constraint, pod
warunkiem że jego warunek zostanie spełniony (np. uzupełnimy wpisy
w tabeli nadrzędnej w przypadku FOREIGN KEY). Możemy również
włączyć constraint bez walidacji istniejących danych. Constraint
będzie w takim wypadku obowiązywał tylko dla danych wprowadzonych
później:

Usuwanie
konstraintów
Aby
zdjąć z tabeli constraint musimy skorzystać z polecenia drop
podając nazwę klucza.
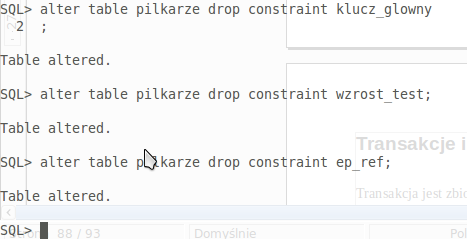
Poniżej
usuwam wszystkie constrainty z tabeli piłkarze.
Widoki
Jeśli
często wykonujemy jakiej zapytanie do bazy danych, np. z użyciem
wielu tabel lub po prostu długie, możemy zdefiniować widok.
Korzystanie z niego będzie o wiele wygodniejsze. Możemy pobierać z
niego dane jak ze zwykłej tabeli. Nagle długie zapytanie z wieloma
parametrami do którego często trzeba coś dodawać możemy zamienić
w mniej więcej coś takiego:
SELECT
* FROM NAZWA_WIDOKU
Widoki
są strukturami całkowicie dynamicznymi, tzn. zapytanie, które je
definiuje w momencie definicji jest tylko sprawdzane pod względem
poprawności składniowej i semantycznej, natomiast nie jest
wykonywane. Zapytanie to jest wykonywane w momencie odwoływania się
do widoku.
Widoki
mają też zastosowanie w przypadku nadawania uprawnień. Możemy
chcieć udostępnić użytkownikowi tylko część danych, lub część
kolumn z tabeli. W takim wypadku tworzymy widok o zadanych
właściwościach, a użytkownikowi zezwalamy na dostęp do widoku a
nie tabeli.
Tworzenie
widoków
CREATE
[OR REPLACE] [FORCE] VIEW NAZWA_WIDOKU AS
TREŚĆ_ZAPYTANIA
[ WITH READ ONLY] [WITH CHECK OPTION]
Aby
stworzyć widok, należy mieć uprawnienia do wszystkich obiektów do
których odnosi się widok.
OR
REPLACE
Dzięki
tej klauzuli w przypadku gdyby widok o takiej nazwie już istniał
zostanie nadpisany przez właśnie tworzony.
FORCE
Wymusza
stworzenie widoku nawet jeśli zapytanie będące podstawą widoku
jest niepoprawne (np. odnosi się do tabeli która jeszcze nie
istnieje).
WITH
READ ONLY
W
niektórych przypadkach można stosować instrukcje DML (np. INSERT)
na widokach, ta instrukcja nawet jeśli formalnie byłoby to możliwe,
uniemożliwia to.
WITH
CHECK OPTION
Ta
opcja sprawia, że w przypadku (jeśli to możliwe dla danego widoku)
nie można wrzucić danych albo zmienić ich w taki sposób że nie
będą widoczne w tym widoku.
Wykonywanie
operacji DML na widokach
W
przypadku zapytań, widoki funkcjonują tak jak tabele. W zależności
od operacji DML widoki dotyczą różne właściwości. W żadnym z
poniższych wypadków nie możemy wykonać operacji jeśli widok
został stworzony z klauzulą WITH READ ONLY.
Update
•
Widok nie może być
oparty na wielu tabelach
•
Nie może zawierać
klauzuli DISTINCT
•
Nie może zawierać
GROUP BY ani funkcji grupowych
•
Nie może zawierać
skorelowanych zapytań
•
Wyrażeń w kolumnie
Delete
•
Widok nie może być
oparty na wielu tabelach
•
Nie może zawierać
klauzuli DISTINCT
•
Nie może zawierać
GROUP BY ani funkcji grupowych
•
Nie może zawierać
skorelowanych zapytań
Insert
•
Widok nie może być
oparty na wielu tabelach
•
Nie może zawierać
klauzuli DISTINCT
•
Nie może zawierać
GROUP BY ani funkcji grupowych
•
Nie może zawierać
skorelowanych zapytań
•
Wyrażeń w kolumnie
•
Tabela, na której
oparty jest widok zawiera kolumnę NOT NULL bez wartości domyślnej
i kolumna ta nie jest odwzorowana w widoku.
•
Jeżeli widok
zostanie utworzony z klauzulą WITH CHECK OPTION, to nie będzie
można wstawić do niego żadnego wiersza, który nie byłby później
widoczny w tym widoku.
Usuwanie
widoków
DROP
VIEW NAZWA_WIDOKU;
Sekwencje
Tworzenie
sekwencji
Sekwencja
jest obiektem podającym kolejne wartości wg ustalonych kryteriów.
Sekwencje stosujemy często w celu tworzenia kluczy głównych tabel.
Po co przy wstawianiu kolejnych wierszy podawać ręcznie kolejny
numerek po którym dany wiersz będziemy identyfikować? Łatwo się
przy tym pomylić i wstawić numer który już istnieje, a poza tym
wiąże się to z dość uciążliwym sprawdzaniem ostatniego
numerka. Niech zrobi to za nas automat!

Na
podstawie wyżej przytoczonego przykładu:
create
sequence
Po
tym następuje podanie nazwy sekwencji. W nazwie sekwencji nie może
być spacji.
Minvalue
Wartość
minimalna jaką może przybrać sekwencja.
Maxvalue
Wartość
maksymalna jaką może przybrać sekwencja.
Start
with
Określa
wartość od jakiej ma się rozpoczynać sekwencja.
Increment
by
Określa
wartość o jaką ma się zmieniać aktualny stan sekwencji po każdym
pobraniu danych.
Jako
parametr tego polecenia możemy również podać liczbę ujemną.
Wartość sekwencji będzie wtedy maleć.
Cycle
/ nocycle
Parametr
ten określa czy sekwencja może się przekręcić (jak licznik
przebiegu w samochodzie) i rozpocząć naliczanie od początku.
Cache
/ nocache
klauzula
CACHE włącza wykonywanie pre-alokacji numerów sekwencji i
przechowywanie ich w pamięci, co skutkuje zwiększeniem szybkości
generacji kolejnych liczb. Klauzula NOCACHE wyłącza tę możliwość.
Domyślnie przyjmowane jest CACHE 20. Wartość podana w CACHE musi
być mniejsza niż MAXVALUE - MINVALUE
Order
/ noorder
Klauzula
ORDER gwarantuje, że kolejne liczby będą generowane w porządku
jakim otrzymane zostały przez system polecenia ich generacji.
Klauzula NOORDER wyłączą tę własność.
Pobieranie
wartości z sekwencji
Do
pobierania danych z sekwencji, wykorzystywane są dwie pseudokolumny
currval i nextval.
Nextval
Służy
do pobierania następnej wartości z sekwencji.
Currval
Służy
do pobierania aktualnej wartości sekwencji. Przed wykorzystaniem
currval należy wykonać przynajmniej raz nextval na danej sekwencji.
W przypadku braku takiej inicjacji, zarówno currval jak i nextval
będą miały tą samą wartość odpowiadającą parametrowi start
with dla danej sekwencji. Pobierać wartości z sekwencji możemy na
dwa sposoby. Wykorzystywać do tego select na tabeli (np. dual) lub w
instrukcjach DML. O tym drugim sposobie będziemy mówić nieco
później. Poniżej przytaczam przykłady pobrania wartości currval
i nextval oraz różnice pomiędzy nimi.

wykorzystanie
sekwencji w instrukcjach DML
Dodając
dane do tabeli często zachodzi konieczność wygenerowania dla
każdego wpisu unikalnego id dla każdego wiersza. Zdarza się że
jest to wymagane z powodu założenia na danej tabeli klucza
głównego. W takiej sytuacji najwygodniej jest skorzystać z
sekwencji. Sekwencje mogą produkować tylko wartości liczbowe.

Usuwanie
sekwencji
Aby
usunąć stworzoną sekwencję należy wykorzystać polecenie drop o
następującej konstrukcji:
DROP
SEQUENCE nazwa_sekwencji;
tak
jak poniżej:

Modyfikacja
sekwencji
Aby
zmienić lub nadać jakiś parametr istniejącej sekwencji stosujemy
konstrukcję:
ALTER
SEQUENCE NAZWA_SEKWENCJI NAZWA PARAMETRU {WARTOŚĆ};
Nie
możemy tylko zmienić parametru START WITH co widać wraz z
przykładami prawidłowego zastosowania ALTER SEQUENCE na poniższym
obrazku:

Indeksy
Indeksy
pozwalają zdecydowanie przyspieszyć wyszukiwanie wierszy w
tabelach.
W
przypadku braku indeksu znalezienie wiersza spełniającego pewien
warunek wymagałoby przejrzenia wiersz po wierszu całej tabeli. W
przypadku dużych i bardzo dużych tabel, takie wyszukiwanie mogłoby
trwać bardzo długo. W związku z drzewiastą konstrukcją indeksu
można szybko znaleźć położenie poszukiwanych wierszy. Sprawia to
że wyszukiwanie trwa zawsze krótko.
Tworzenie
indeksu
Ogólna
konstrukcja polecenia tworzącego indeks:
CREATE
INDEX NAZWA_INDEKSU ON NAZWA_TABELI (KOLUMNA);
Indeksy możemy zakładać na więcej niż jednej kolumnie. Wystarczy dodać je po przecinku.
Indeksy
warto zakładać na tych kolumnach które często występują w
zapytaniach jako warunek w filtracji wierszy lub kolumna po której
grupujemy. Indeksy przyspieszają pobieranie danych, ale spowalniają
ich dodawanie/zmianę. Wynika to z tego, że informacje o nowych
danych muszą zostać dodane nie tylko do tabeli ale również do
indeksu.
Usuwanie
indeksu
DROP
INDEX NAZWA_INDEKSU;
Linki
bazodanowe
Linki
bazodanowe są odwołaniami do innej bazy danych, mogącej znajdować
się nawet na odległym (fizycznie) serwerze. Upraszczają pracę na
wielu bazach danych, ponieważ możemy korzystać z innych baz w
podobny sposób jak ze schematów innych użytkowników. Poniżej
widzimy sposób tworzenia linka bazodanowego.
CREATE
DATABASE LINK NAZWA_LINKU
CONNECT
TO NAZWA_UZYTKOWNIKA IDENTIFIED BY
HASLO
USING
ALIAS_BAZY
Przykładowe
zastosowanie:

Jak
widać stworzyliśmy link bazodanowy odnoszący się do bazy danych
określonej w pliku tnsnames.ora jako XE. Plik ten zawiera
szczegółowe dane dotyczące połączenia 'xe'. Dzięki wpisowi w
tym pliku system wie do jakiej bazy danych się odwoływać.
Możemy
również podać adres IP innego serwera Oracle, tak jak to widać na
poniższej ilustracji:
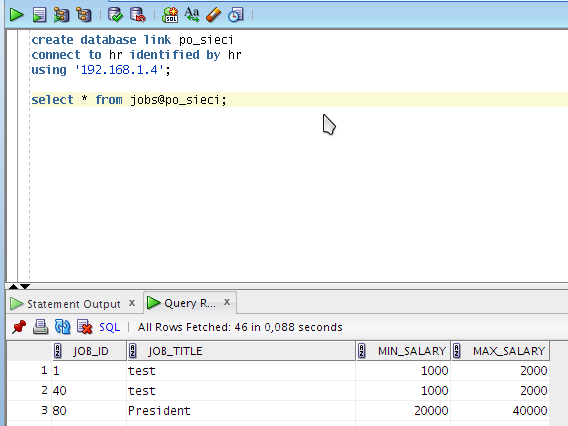
Zdalny
serwer Oracle na podstawie danych autoryzacyjnych przekieruje nas do
właściwego schematu. Od momentu stworzenia linka bazodanowego
możemy korzystać z obiektów w zdalnej bazie danych tak jak z
lokalnych, musimy jedynie podawać „@nazwa_linku” po nazwie
obiektu znajdującego się w tej bazie.
hej, świetny tutek! W jednym miejscu jest nie po polsku tj. dla 'with check option'. Można by tam wrzucić więcej niż jedno zdanie bo klauzula jest nie oczywista. Szacun.
OdpowiedzUsuń