Rank()
Funkcja Rank() zasadniczo działa na tej samej zasadzie jak Dense_rank(), jednak jeśli pojawią się dwie pozycje na tym ramym poziomie w rankingu, pozostawiane jest miejsce w numeracji. Zwróć uwagę na Pozycje Kochhar i Russell.

Row_number()
Funkcja row_number() służy nadawaniu numerów kolejnym wierszom w grupie. Grupą oczywiście może być również cały zbiór bez podziału na partycje. Często na szkoleniach słyszę pytanie: „Czym w takim razie różni się row_number() od np. dense_rank()?” - służą zupełnie innym celom, zauważ że w przypadku funkcji rankingowych dwa rekordy mogły zająć miejsce ex equo – tutaj nie ma takiej możliwości. Dense_rank oraz rank przyznają numer na podstawie kryteriów – row_number to takie „bezmyślne” numerowanie kolejnych wierszy w ramach partycji.

Wyświetlanie TOP N wierszy
Niekiedy zachodzi potrzeba wyświetlenia tylko pierwszych X wierszy z wyniku. Istnieje na to kilka metod wykorzystywanych w zależności od tego czy korzystamy z grupowania, kryteriów wg jakich systematyzujemy kolejność pojawiania się wierszy w wyniku.
W Oracle jest funkcja rownum (jest to coś innego niż row_number()) która podczas generowania wyniku nadaje każdemu kolejnemu wierszowi kolejny numer. Działa trochę jak samoodnawiająca się sekwencja. Bez wykorzystania podzapytań (o tym dalej) możemy ją wykorzystać do ograniczenia tylko początkowej sekcji wierszy.

Nie moglibyśmy tego zapytania przerobić dodając dodatkowy warunek tego typu:
where rownum<=10 and rownum >=4 a więc wyświetlając zakres inny niż zaczynający się od początku wyniku zapytania. Zapytanie zwróciłoby nam 0 wierszy. Dzieje się tak dlatego, że rownum jest funkcją która działa dynamicznie na wynikach. Nie możemy przecież sprawdzać i porównywać jakiejś wartości zanim zostanie ona wygenerowana.
Nic nie stoi jednak na przeszkodzie, aby zamienić wartość dynamicznie tworzoną w statyczną nadając jej alias. Kiedy odwołujemy się do aliasu nie generujemy już nowych wartości. Każdorazowe odwołanie się do „rownum” powoduje wywołanie nowej wartości. Tworząc podzapytanie po klauzuli from zamiast nazwy tabeli, w zapytaniu nadrzędnym odwołujemy się do aliasu, a więc do statycznej wartości – tak jakby to była zwykła kolumna. Dzięki temu możemy operować na zakresach.

Jeżeli chcemy wyświetlić zakresy w ramach grup (nie możemy zastosować zwykłych funkcji agregujących które zwracają jeden wynik dla grupy) musimy połączyć przed momentem zaprezentowaną technikę, oraz funkcje analityczne. Zakresy zaczynające się od początku wyników w grupach.
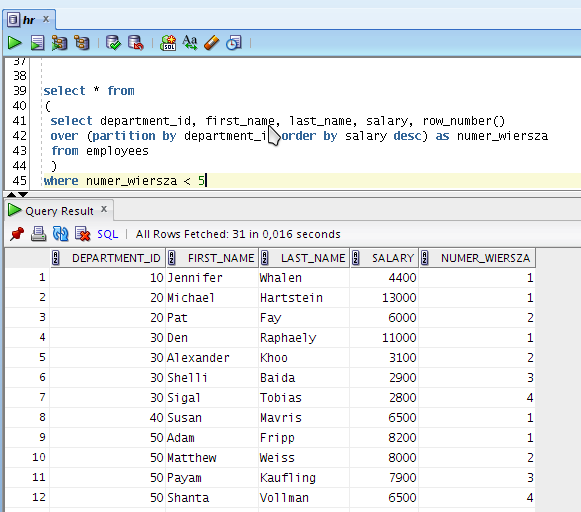
Zakresy nie zaczynające się od początku wyników w grupie:

Istnieją oczywiście trudniejsze i nieco bardziej „wyrafinowane” metody osiągnięcia podobnych rezultatów przy użyciu tylko funkcji analitycznych, jednak wiązałoby się to z zapoznaniem się z szeregiem nowych zagadnień, którymi na tym kursie nie będziemy się zajmowali.
Cume_dist()
Funkcja CUME_DIST oblicza rozkład wartości w grupie wartości. Może przyjmować, wartości większe niż 0 ale mniejsze lub równe 1. Liczba ta rozumiana jest jako procent rekordów poprzedzających ten rekord w rankingu z uwzględnieniem bieżącego wiersza. Przyjmuje jako argument każdy typ danych numerycznych lub nienumerycznych który może być niejawnie konwertowany na typ numeryczny. Oblicza względną pozycję określonej wartości w grupie wartości.
A teraz po polsku: jesteśmy np. w stanie stwierdzić że 32% osób w dziale IT zarabia tyle ile programista Krzysiek lub mniej. Zakres zależy od sortowania. Jeśli mamy ustawione sortowanie rosnące – zakres będzie dotyczyć Krzyśka oraz osób zarabiających mniej . Jeśli malejące, wtedy Krzyśka i osób zarabiających więcej. Zastosowanie przykładowe:

Zastosowanie takie żeby można było to względnie łatwo pojąć, chociaż w sumie mało życiowe:)

Kochhar zarabia rocznie 17000$. W dziale w którym pracuje (nr 90) pracuje trzech pracowników.
On stanowi 0,66(6) % pracowników tego działu którzy otrzymują zarobki o identycznej wysokości jak on. Wniosek? Dwie trzecie ludzi w dziale 90 zarabia 17000$ rocznie.
Spójrz na Kinga. Zarabia 24000$ rocznie. Stanowi 100% osób z tego działu zarabiających taką kwotę. Wniosek? Tylko on ma taką pensję w tym dziale.
Zasadniczo działa tak jak cume_dist, przy czym w obliczeniach nie uwzględnia bieżącego rekordu.
Porównaj wyniki cume_dist i percent_rank. Cume_dist:

percent_rank:

Andrzeju, omawiając row_number() napisałeś: " Często na szkoleniach słyszę pytanie: „Czym w takim razie różni się row_number() od np. dense_rank()?”" - to jest bezsensowne pytanie, bo różnicę widać gołym okiem.
OdpowiedzUsuńBardziej zapytałbym, jaka jest różnica między Row_number()a nadawanym indexem dla wiersza. Skoro zarówno jedno, jak i drugie mają za zadanie ponumerować kolejno wiersze.
dobrze, chyba sam sobie powoli zacząłem odpowiadać na zadane pytanie. Chodzi o to, że to my mamy dynamiczną kontrolę, jaki index zostanie przypisany do danego wiersza, a jeżeli chodzi o row_number(), to postępowanie jest tu iteracyjne. Dobrze myślę?
OdpowiedzUsuńJeżeli masz jeszcze jakieś różnice dla mnie, to pisz :)